 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Selection with Conjunctions of Decision Stumps and Learning from Microarray Data
Paper and Code
May 04, 2010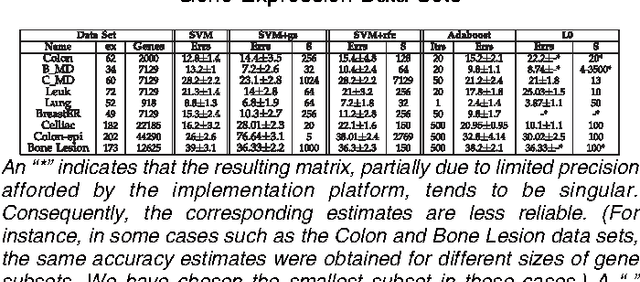



One of the objectives of designing feature selection learning algorithms is to obtain classifiers that depend on a small number of attributes and have verifiable future performance guarantees. There are few, if any, approaches that successfully address the two goals simultaneously. Performance guarantees become crucial for tasks such as microarray data analysis due to very small sample sizes resulting in limited empirical evaluation. To the best of our knowledge, such algorithms that give theoretical bounds on the future performance have not been proposed so far in the context of the classification of gene expression data. In this work, we investigate the premise of learning a conjunction (or disjunction) of decision stumps in Occam's Razor, Sample Compression, and PAC-Bayes learning settings for identifying a small subset of attributes that can be used to perform reliable classification tasks. We apply the proposed approaches for gene identification from DNA microarray data and compare our results to those of well known successful approaches proposed for the task. We show that our algorithm not only finds hypotheses with much smaller number of genes while giving competitive classification accuracy but also have tight risk guarantees on future performance unlike other approaches. The proposed approaches are general and extensible in terms of both designing novel algorithms and application to other domains.