 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature-level augmentation to improve robustness of deep neural networks to affine transformations
Paper and Code
Feb 15, 2022
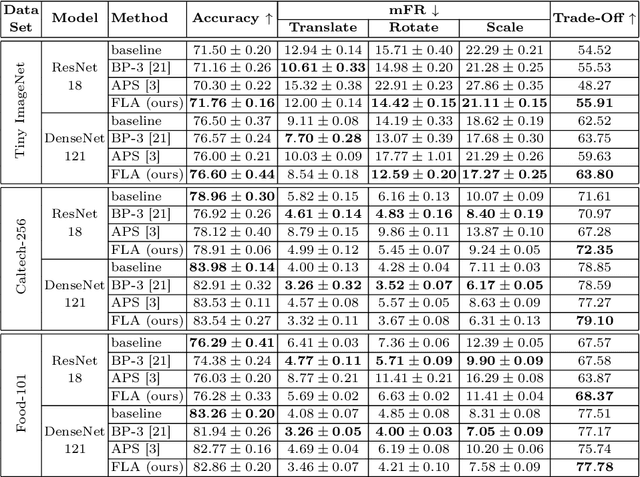

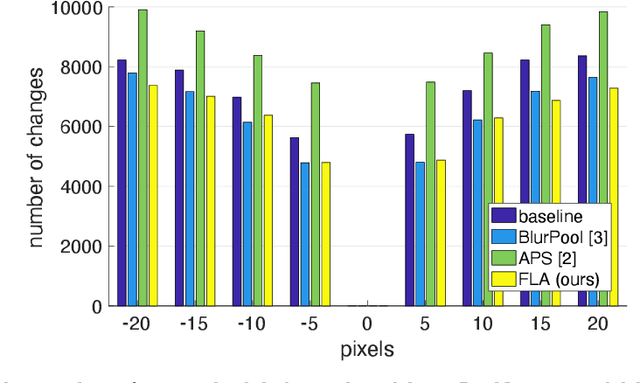
Recent studies revealed that convolutional neural networks do not generalize well to small image transformations, e.g. rotations by a few degrees or translations of a few pixels. To improve the robustness to such transformations, we propose to introduce data augmentation at intermediate layers of the neural architecture, in addition to the common data augmentation applied on the input images. By introducing small perturbations to activation maps (features) at various levels, we develop the capacity of the neural network to cope with such transformations. We conduct experiments on three image classification benchmarks (Tiny ImageNet, Caltech-256 and Food-101), considering two different convolutional architectures (ResNet-18 and DenseNet-121). When compared with two state-of-the-art stabilization methods, the empirical results show that our approach consistently attains the best trade-off between accuracy and mean flip rate.