 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Online Video Super-Resolution with Deformable Attention Pyramid
Paper and Code
Feb 03, 2022

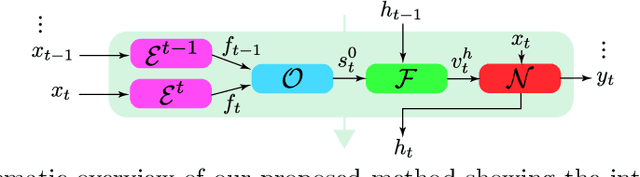

Video super-resolution (VSR) has many applications that pose strict causal, real-time, and latency constraints, including video streaming and TV. We address the VSR problem under these settings, which poses additional important challenges since information from future frames are unavailable. Importantly, designing efficient, yet effective frame alignment and fusion modules remain central problems. In this work, we propose a recurrent VSR architecture based on a deformable attention pyramid (DAP). Our DAP aligns and integrates information from the recurrent state into the current frame prediction. To circumvent the computational cost of traditional attention-based methods, we only attend to a limited number of spatial locations, which are dynamically predicted by the DAP. Comprehensive experiments and analysis of the proposed key innovations show the effectiveness of our approach. We significantly reduce processing time in comparison to state-of-the-art methods, while maintaining a high performance. We surpass state-of-the-art method EDVR-M on two standard benchmarks with a speed-up of over 3x.