 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Accurate Gaussian Kernel Ridge Regression Using Matrix Decompositions for Preconditioning
Paper and Code
May 25, 2019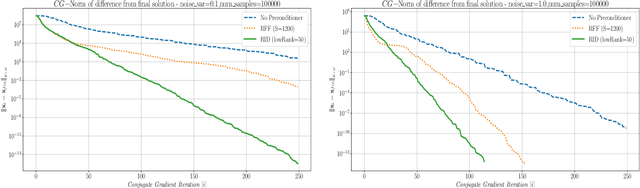
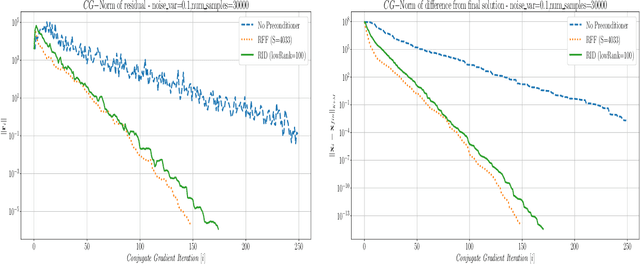
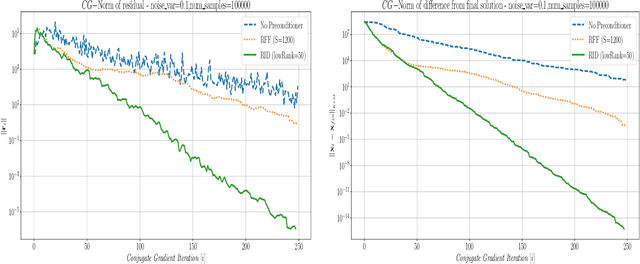
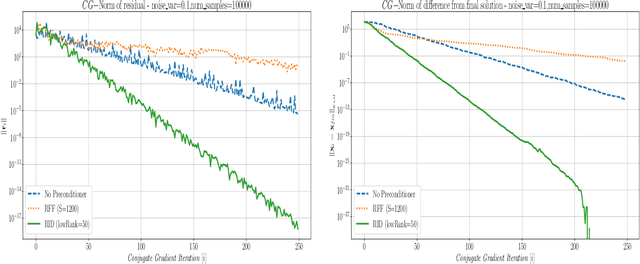
This paper presents a method for building a preconditioner for a kernel ridge regression problem, where the preconditioner is not only effective in its ability to reduce the condition number substantially, but also efficient in its application in terms of computational cost and memory consumption. The suggested approach is based on randomized matrix decomposition methods, combined with the fast multipole method to achieve an algorithm that can process large datasets in complexity linear to the number of data points. In addition, a detailed theoretical analysis is provided, including an upper bound to the condition number. Finally, for Gaussian kernels, the analysis shows that the required rank for a desired condition number can be determined directly from the dataset itself without performing any analysis on the kernel matrix.