 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Algorithm and Implementation of Dissimilarity Self-Organizing Maps
Paper and Code
Sep 21, 2007

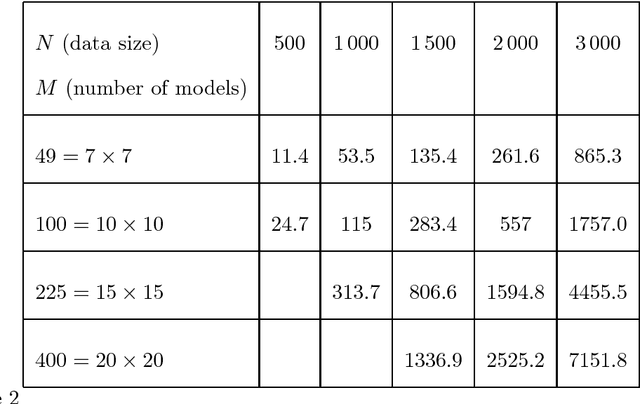

In many real world applications, data cannot be accurately represented by vectors. In those situations, one possible solution is to rely on dissimilarity measures that enable sensible comparison between observations. Kohonen's Self-Organizing Map (SOM) has been adapted to data described only through their dissimilarity matrix. This algorithm provides both non linear projection and clustering of non vector data. Unfortunately, the algorithm suffers from a high cost that makes it quite difficult to use with voluminous data sets. In this paper, we propose a new algorithm that provides an important reduction of the theoretical cost of the dissimilarity SOM without changing its outcome (the results are exactly the same as the ones obtained with the original algorithm). Moreover, we introduce implementation methods that result in very short running times. Improvements deduced from the theoretical cost model are validated on simulated and real world data (a word list clustering problem). We also demonstrate that the proposed implementation methods reduce by a factor up to 3 the running time of the fast algorithm over a standard implementation.