Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFarkas layers: don't shift the data, fix the geometry
Paper and Code
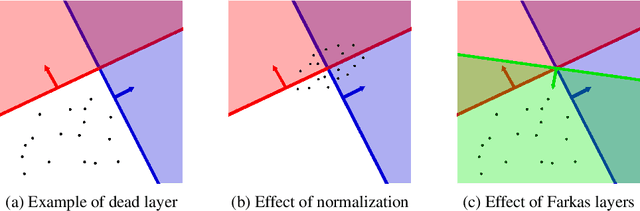


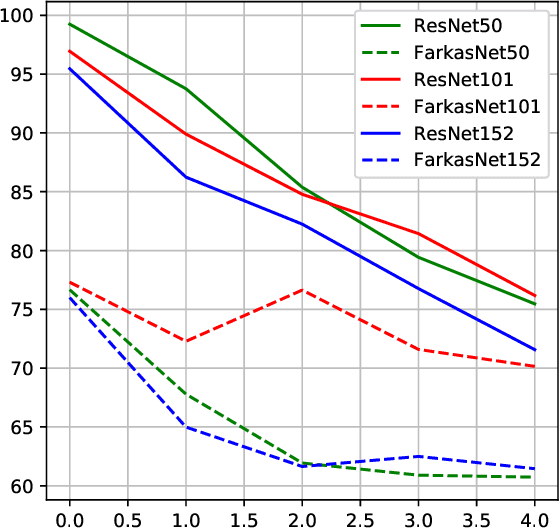
Successfully training deep neural networks often requires either batch normalization, appropriate weight initialization, both of which come with their own challenges. We propose an alternative, geometrically motivated method for training. Using elementary results from linear programming, we introduce Farkas layers: a method that ensures at least one neuron is active at a given layer. Focusing on residual networks with ReLU activation, we empirically demonstrate a significant improvement in training capacity in the absence of batch normalization or methods of initialization across a broad range of network sizes on benchmark datasets.
View paper on
 OpenReview
OpenReview