 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAIR4Cov: Fused Audio Instance and Representation for COVID-19 Detection
Paper and Code
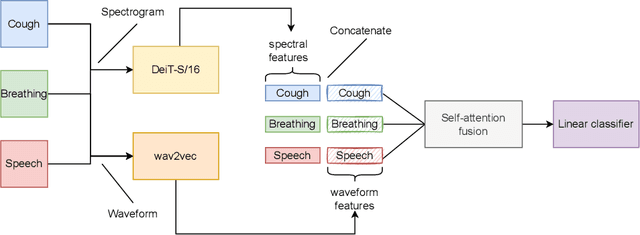



Audio-based classification techniques on body sounds have long been studied to support diagnostic decisions, particularly in pulmonary diseases. In response to the urgency of the COVID-19 pandemic, a growing number of models are developed to identify COVID-19 patients based on acoustic input. Most models focus on cough because the dry cough is the best-known symptom of COVID-19. However, other body sounds, such as breath and speech, have also been revealed to correlate with COVID-19 as well. In this work, rather than relying on a specific body sound, we propose Fused Audio Instance and Representation for COVID-19 Detection (FAIR4Cov). It relies on constructing a joint feature vector obtained from a plurality of body sounds in waveform and spectrogram representation. The core component of FAIR4Cov is a self-attention fusion unit that is trained to establish the relation of multiple body sounds and audio representations and integrate it into a compact feature vector. We set up our experiments on different combinations of body sounds using only waveform, spectrogram, and a joint representation of waveform and spectrogram. Our findings show that the use of self-attention to combine extracted features from cough, breath, and speech sounds leads to the best performance with an Area Under the Receiver Operating Characteristic Curve (AUC) score of 0.8658, a sensitivity of 0.8057, and a specificity of 0.7958. This AUC is 0.0227 higher than the one of the models trained on spectrograms only and 0.0847 higher than the one of the models trained on waveforms only. The results demonstrate that the combination of spectrogram with waveform representation helps to enrich the extracted features and outperforms the models with single representation.