 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair and Argumentative Language Modeling for Computational Argumentation
Paper and Code

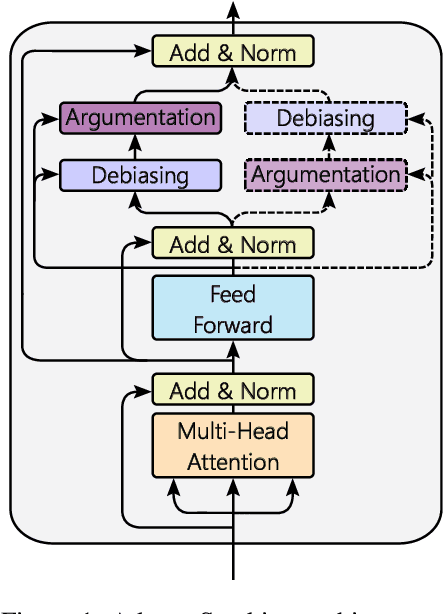


Although much work in NLP has focused on measuring and mitigating stereotypical bias in semantic spaces, research addressing bias in computational argumentation is still in its infancy. In this paper, we address this research gap and conduct a thorough investigation of bias in argumentative language models. To this end, we introduce ABBA, a novel resource for bias measurement specifically tailored to argumentation. We employ our resource to assess the effect of argumentative fine-tuning and debiasing on the intrinsic bias found in transformer-based language models using a lightweight adapter-based approach that is more sustainable and parameter-efficient than full fine-tuning. Finally, we analyze the potential impact of language model debiasing on the performance in argument quality prediction, a downstream task of computational argumentation. Our results show that we are able to successfully and sustainably remove bias in general and argumentative language models while preserving (and sometimes improving) model performance in downstream tasks. We make all experimental code and data available at https://github.com/umanlp/FairArgumentativeLM.