 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending AdamW by Leveraging Its Second Moment and Magnitude
Paper and Code
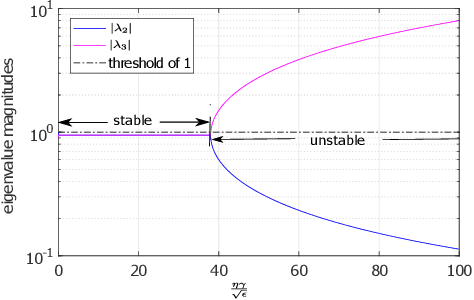
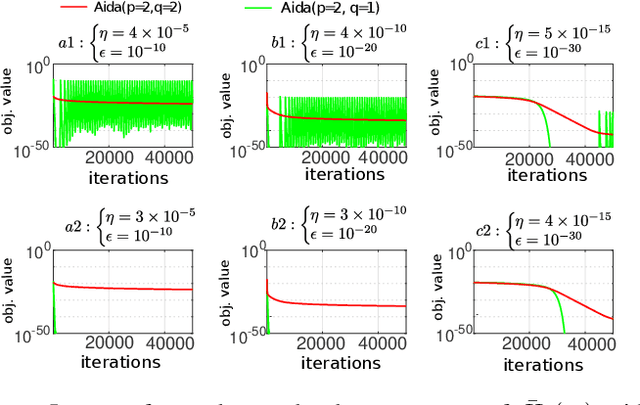
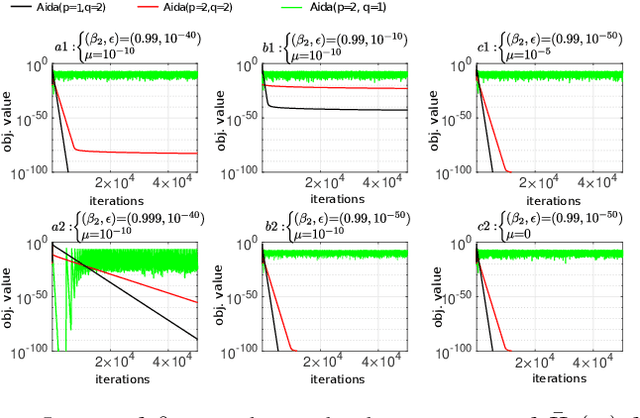
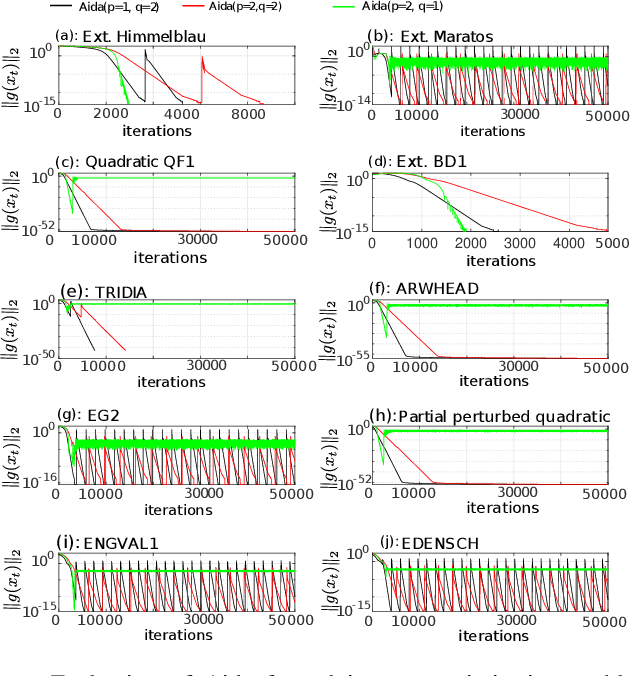
Recent work [4] analyses the local convergence of Adam in a neighbourhood of an optimal solution for a twice-differentiable function. It is found that the learning rate has to be sufficiently small to ensure local stability of the optimal solution. The above convergence results also hold for AdamW. In this work, we propose a new adaptive optimisation method by extending AdamW in two aspects with the purpose to relax the requirement on small learning rate for local stability, which we refer to as Aida. Firstly, we consider tracking the 2nd moment r_t of the pth power of the gradient-magnitudes. r_t reduces to v_t of AdamW when p=2. Suppose {m_t} is the first moment of AdamW. It is known that the update direction m_{t+1}/(v_{t+1}+epsilon)^0.5 (or m_{t+1}/(v_{t+1}^0.5+epsilon) of AdamW (or Adam) can be decomposed as the sign vector sign(m_{t+1}) multiplied elementwise by a vector of magnitudes |m_{t+1}|/(v_{t+1}+epsilon)^0.5 (or |m_{t+1}|/(v_{t+1}^0.5+epsilon)). Aida is designed to compute the qth power of the magnitude in the form of |m_{t+1}|^q/(r_{t+1}+epsilon)^(q/p) (or |m_{t+1}|^q/((r_{t+1})^(q/p)+epsilon)), which reduces to that of AdamW when (p,q)=(2,1). Suppose the origin 0 is a local optimal solution of a twice-differentiable function. It is found theoretically that when q>1 and p>1 in Aida, the origin 0 is locally stable only when the weight-decay is non-zero. Experiments are conducted for solving ten toy optimisation problems and training Transformer and Swin-Transformer for two deep learning (DL) tasks. The empirical study demonstrates that in a number of scenarios (including the two DL tasks), Aida with particular setups of (p,q) not equal to (2,1) outperforms the setup (p,q)=(2,1) of AdamW.