 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExponential Convergence Rates of Classification Errors on Learning with SGD and Random Features
Paper and Code
Nov 13, 2019
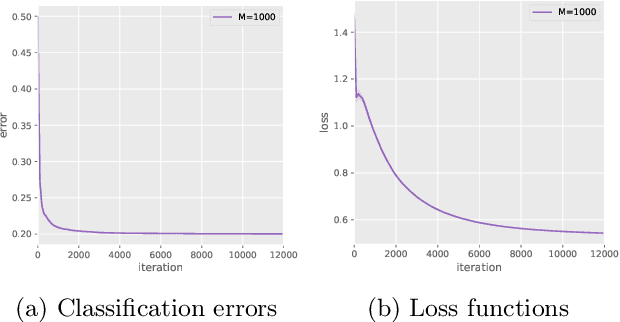
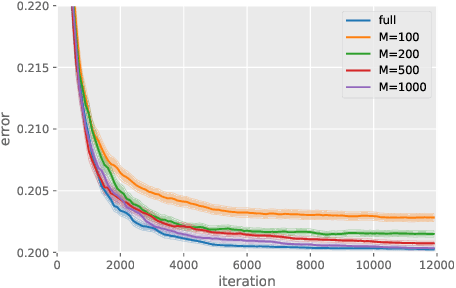
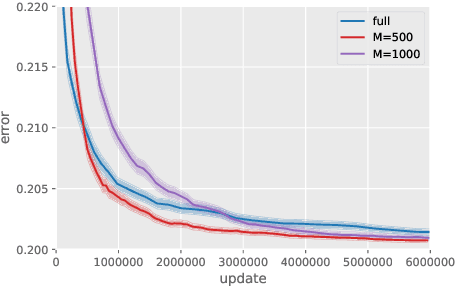
Although kernel methods are widely used in many learning problems, they have poor scalability to large datasets. To address this problem, sketching and stochastic gradient methods are the most commonly used techniques to derive efficient large-scale learning algorithms. In this study, we consider solving a binary classification problem using random features and stochastic gradient descent. In recent research, an exponential convergence rate of the expected classification error under the strong low-noise condition has been shown. We extend these analyses to a random features setting, analyzing the error induced by the approximation of random features in terms of the distance between the generated hypothesis including population risk minimizers and empirical risk minimizers when using general Lipschitz loss functions, to show that an exponential convergence of the expected classification error is achieved even if random features approximation is applied. Additionally, we demonstrate that the convergence rate does not depend on the number of features and there is a significant computational benefit in using random features in classification problems because of the strong low-noise condition.