 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Reciprocal Attention for Salient Object Detection by Cooperative Learning
Paper and Code
Sep 18, 2019
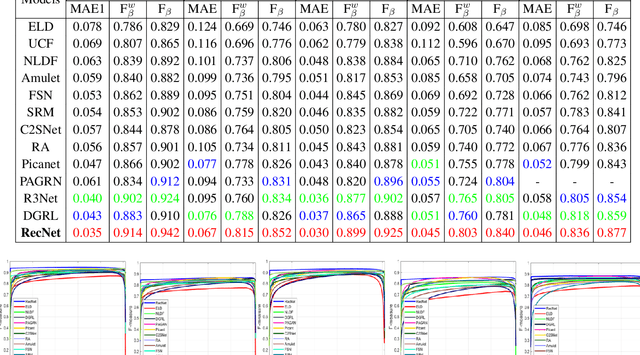
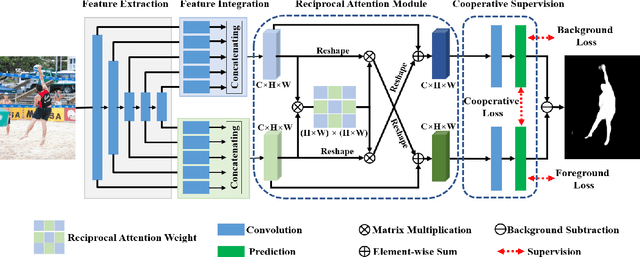
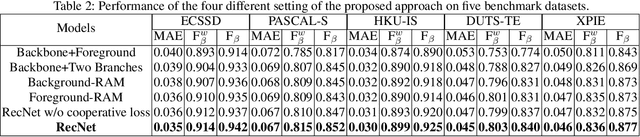
Typically, objects with the same semantics are not always prominent in images containing different backgrounds. Motivated by this observation that accurately salient object detection is related to both foreground and background, we proposed a novel cooperative attention mechanism that jointly considers reciprocal relationships between background and foreground for efficient salient object detection. Concretely, we first aggregate the features at each side-out of traditional dilated FCN to extract the initial foreground and background local responses respectively. Then taking these responses as input, reciprocal attention module adaptively models the nonlocal dependencies between any two pixels of the foreground and background features, which is then aggregated with local features in a mutual reinforced way so as to enhance each branch to generate more discriminative foreground and background saliency map. Besides, cooperative losses are particularly designed to guide the multi-task learning of foreground and background branches, which encourages our network to obtain more complementary predictions with clear boundaries. At last, a simple but effective fusion strategy is utilized to produce the final saliency map. Comprehensive experimental results on five benchmark datasets demonstrate that our proposed method performs favorably against the state-of-the-art approaches in terms of all compared evaluation metrics.