 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Optical-Flow-Guided Motion and Detection-Based Appearance for Temporal Sentence Grounding
Paper and Code
Mar 06, 2022
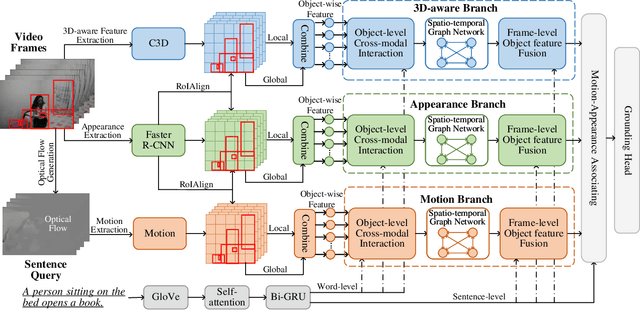


Temporal sentence grounding aims to localize a target segment in an untrimmed video semantically according to a given sentence query. Most previous works focus on learning frame-level features of each whole frame in the entire video, and directly match them with the textual information. Such frame-level feature extraction leads to the obstacles of these methods in distinguishing ambiguous video frames with complicated contents and subtle appearance differences, thus limiting their performance. In order to differentiate fine-grained appearance similarities among consecutive frames, some state-of-the-art methods additionally employ a detection model like Faster R-CNN to obtain detailed object-level features in each frame for filtering out the redundant background contents. However, these methods suffer from missing motion analysis since the object detection module in Faster R-CNN lacks temporal modeling. To alleviate the above limitations, in this paper, we propose a novel Motion- and Appearance-guided 3D Semantic Reasoning Network (MA3SRN), which incorporates optical-flow-guided motion-aware, detection-based appearance-aware, and 3D-aware object-level features to better reason the spatial-temporal object relations for accurately modelling the activity among consecutive frames. Specifically, we first develop three individual branches for motion, appearance, and 3D encoding separately to learn fine-grained motion-guided, appearance-guided, and 3D-aware object features, respectively. Then, both motion and appearance information from corresponding branches are associated to enhance the 3D-aware features for the final precise grounding. Extensive experiments on three challenging datasets (ActivityNet Caption, Charades-STA and TACoS) demonstrate that the proposed MA3SRN model achieves a new state-of-the-art.