 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring High-quality Target Domain Information for Unsupervised Domain Adaptive Semantic Segmentation
Paper and Code
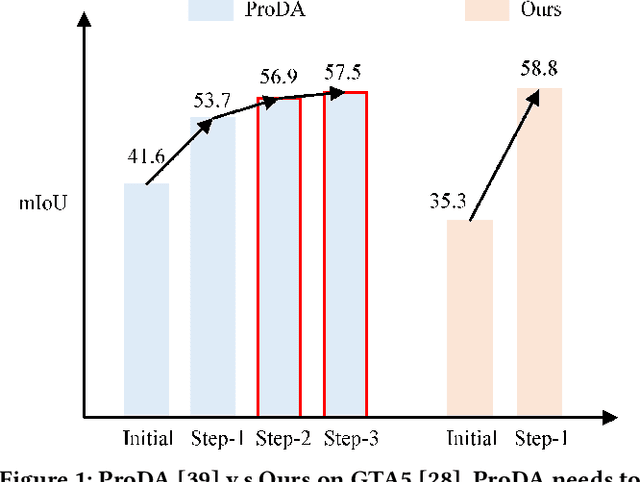



In unsupervised domain adaptive (UDA) semantic segmentation, the distillation based methods are currently dominant in performance. However, the distillation technique requires complicate multi-stage process and many training tricks. In this paper, we propose a simple yet effective method that can achieve competitive performance to the advanced distillation methods. Our core idea is to fully explore the target-domain information from the views of boundaries and features. First, we propose a novel mix-up strategy to generate high-quality target-domain boundaries with ground-truth labels. Different from the source-domain boundaries in previous works, we select the high-confidence target-domain areas and then paste them to the source-domain images. Such a strategy can generate the object boundaries in target domain (edge of target-domain object areas) with the correct labels. Consequently, the boundary information of target domain can be effectively captured by learning on the mixed-up samples. Second, we design a multi-level contrastive loss to improve the representation of target-domain data, including pixel-level and prototype-level contrastive learning. By combining two proposed methods, more discriminative features can be extracted and hard object boundaries can be better addressed for the target domain. The experimental results on two commonly adopted benchmarks (\textit{i.e.}, GTA5 $\rightarrow$ Cityscapes and SYNTHIA $\rightarrow$ Cityscapes) show that our method achieves competitive performance to complicated distillation methods. Notably, for the SYNTHIA$\rightarrow$ Cityscapes scenario, our method achieves the state-of-the-art performance with $57.8\%$ mIoU and $64.6\%$ mIoU on 16 classes and 13 classes. Code is available at https://github.com/ljjcoder/EHTDI.