 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Deep 3D Spatial Encodings for Large-Scale 3D Scene Understanding
Paper and Code
Nov 29, 2020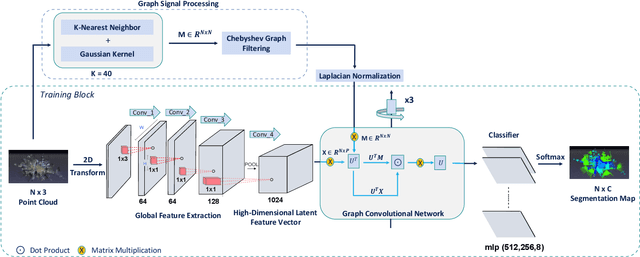
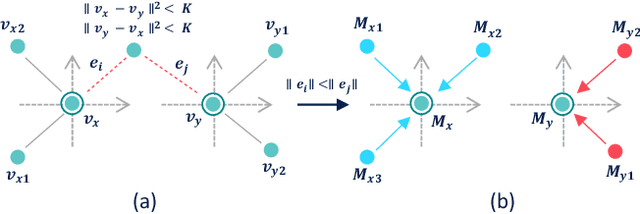
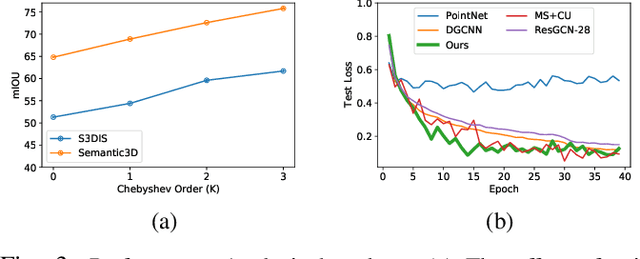
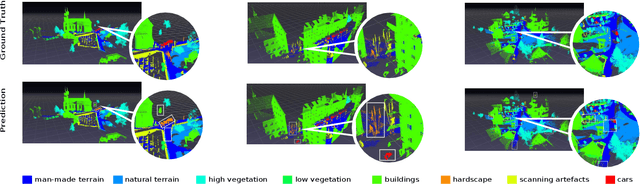
Semantic segmentation of raw 3D point clouds is an essential component in 3D scene analysis, but it poses several challenges, primarily due to the non-Euclidean nature of 3D point clouds. Although, several deep learning based approaches have been proposed to address this task, but almost all of them emphasized on using the latent (global) feature representations from traditional convolutional neural networks (CNN), resulting in severe loss of spatial information, thus failing to model the geometry of the underlying 3D objects, that plays an important role in remote sensing 3D scenes. In this letter, we have proposed an alternative approach to overcome the limitations of CNN based approaches by encoding the spatial features of raw 3D point clouds into undirected symmetrical graph models. These encodings are then combined with a high-dimensional feature vector extracted from a traditional CNN into a localized graph convolution operator that outputs the required 3D segmentation map. We have performed experiments on two standard benchmark datasets (including an outdoor aerial remote sensing dataset and an indoor synthetic dataset). The proposed method achieves on par state-of-the-art accuracy with improved training time and model stability thus indicating strong potential for further research towards a generalized state-of-the-art method for 3D scene understanding.