 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Adam-like Optimization Algorithms to Improve the Performance of Convolutional Neural Networks
Paper and Code
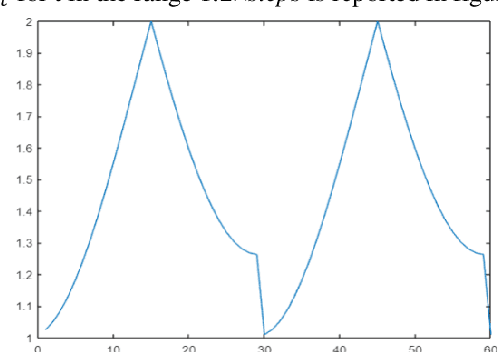
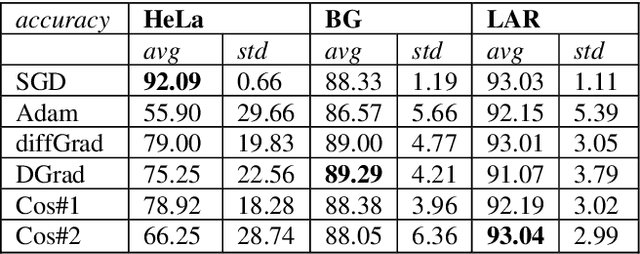
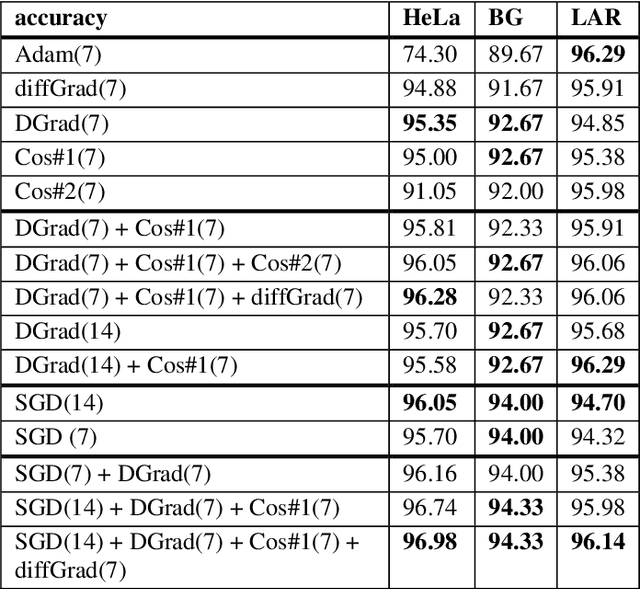
Stochastic gradient descent (SGD) is the main approach for training deep networks: it moves towards the optimum of the cost function by iteratively updating the parameters of a model in the direction of the gradient of the loss evaluated on a minibatch. Several variants of SGD have been proposed to make adaptive step sizes for each parameter (adaptive gradient) and take into account the previous updates (momentum). Among several alternative of SGD the most popular are AdaGrad, AdaDelta, RMSProp and Adam which scale coordinates of the gradient by square roots of some form of averaging of the squared coordinates in the past gradients and automatically adjust the learning rate on a parameter basis. In this work, we compare Adam based variants based on the difference between the present and the past gradients, the step size is adjusted for each parameter. We run several tests benchmarking proposed methods using medical image data. The experiments are performed using ResNet50 architecture neural network. Moreover, we have tested ensemble of networks and the fusion with ResNet50 trained with stochastic gradient descent. To combine the set of ResNet50 the simple sum rule has been applied. Proposed ensemble obtains very high performance, it obtains accuracy comparable or better than actual state of the art. To improve reproducibility and research efficiency the MATLAB source code used for this research is available at GitHub: https://github.com/LorisNanni.