 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining latent representations of generative models with large multimodal models
Paper and Code
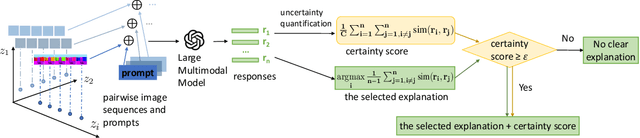

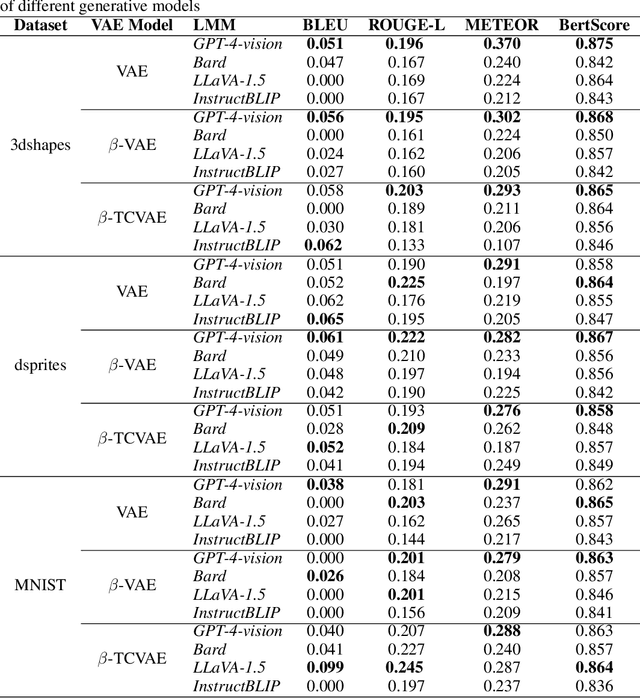

Learning interpretable representations of data generative latent factors is an important topic for the development of artificial intelligence. With the rise of the large multimodal model, it can align images with text to generate answers. In this work, we propose a framework to comprehensively explain each latent factor in the generative models using a large multimodal model. We further measure the uncertainty of our generated explanations, quantitatively evaluate the performance of explanation generation among multiple large multimodal models, and qualitatively visualize the variations of each latent factor to learn the disentanglement effects of different generative models on explanations. Finally, we discuss the explanatory capabilities and limitations of state-of-the-art large multimodal models.