 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Explainability: Towards Deeper Actionable Insights into Deep Learning through Second-order Explainability
Paper and Code
Jun 14, 2023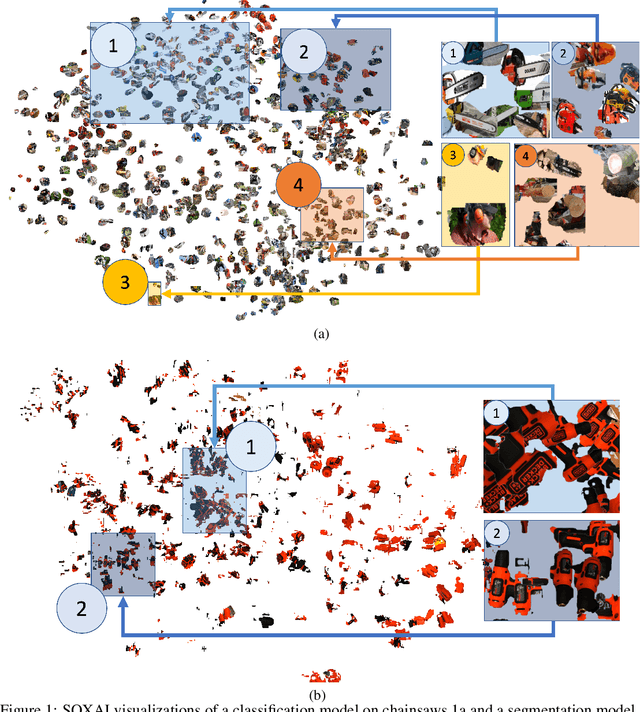

Explainability plays a crucial role in providing a more comprehensive understanding of deep learning models' behaviour. This allows for thorough validation of the model's performance, ensuring that its decisions are based on relevant visual indicators and not biased toward irrelevant patterns existing in training data. However, existing methods provide only instance-level explainability, which requires manual analysis of each sample. Such manual review is time-consuming and prone to human biases. To address this issue, the concept of second-order explainable AI (SOXAI) was recently proposed to extend explainable AI (XAI) from the instance level to the dataset level. SOXAI automates the analysis of the connections between quantitative explanations and dataset biases by identifying prevalent concepts. In this work, we explore the use of this higher-level interpretation of a deep neural network's behaviour to allows us to "explain the explainability" for actionable insights. Specifically, we demonstrate for the first time, via example classification and segmentation cases, that eliminating irrelevant concepts from the training set based on actionable insights from SOXAI can enhance a model's performance.