 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpert and Crowd-Guided Affect Annotation and Prediction
Paper and Code
Dec 15, 2021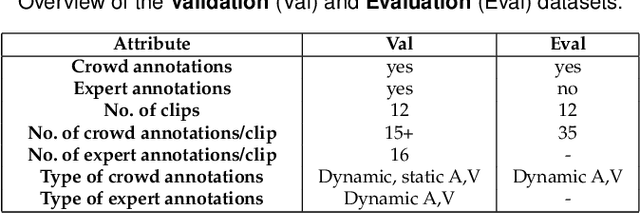
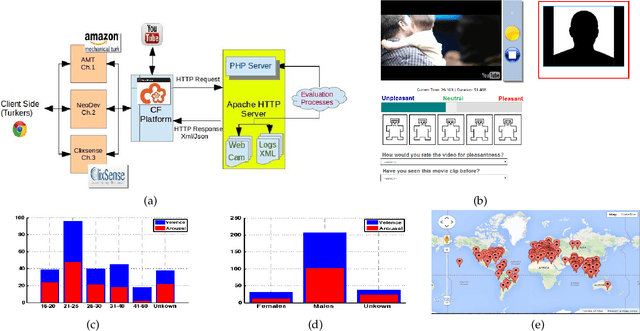

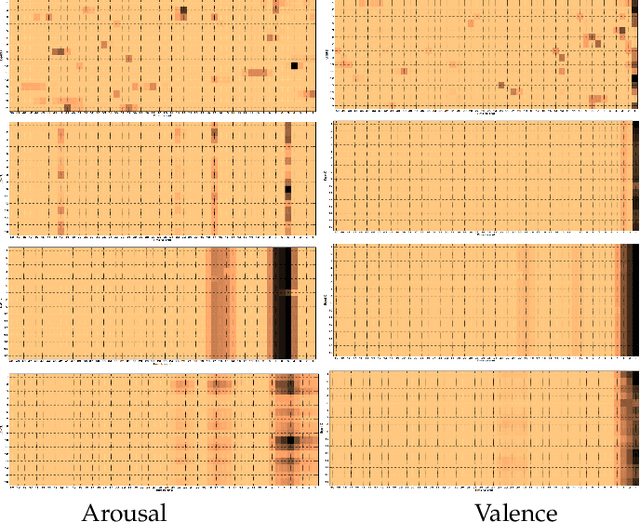
We employ crowdsourcing to acquire time-continuous affective annotations for movie clips, and refine noisy models trained from these crowd annotations incorporating expert information within a Multi-task Learning (MTL) framework. We propose a novel \textbf{e}xpert \textbf{g}uided MTL (EG-MTL) algorithm, which minimizes the loss with respect to both crowd and expert labels to learn a set of weights corresponding to each movie clip for which crowd annotations are acquired. We employ EG-MTL to solve two problems, namely, \textbf{\texttt{P1}}: where dynamic annotations acquired from both experts and crowdworkers for the \textbf{Validation} set are used to train a regression model with audio-visual clip descriptors as features, and predict dynamic arousal and valence levels on 5--15 second snippets derived from the clips; and \textbf{\texttt{P2}}: where a classification model trained on the \textbf{Validation} set using dynamic crowd and expert annotations (as features) and static affective clip labels is used for binary emotion recognition on the \textbf{Evaluation} set for which only dynamic crowd annotations are available. Observed experimental results confirm the effectiveness of the EG-MTL algorithm, which is reflected via improved arousal and valence estimation for \textbf{\texttt{P1}}, and higher recognition accuracy for \textbf{\texttt{P2}}.