 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExcessive Invariance Causes Adversarial Vulnerability
Paper and Code


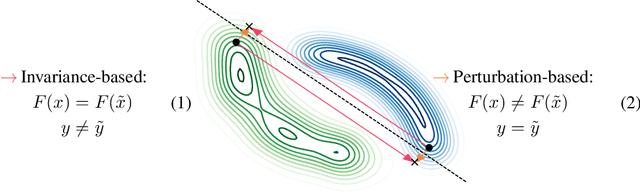

Despite their impressive performance, deep neural networks exhibit striking failures on out-of-distribution inputs. One core idea of adversarial example research is to reveal neural network errors under such distribution shift. We decompose these errors into two complementary sources: sensitivity and invariance. We show deep networks are not only too sensitive to task-irrelevant changes of their input, as is well-known from epsilon-adversarial examples, but are also too invariant to a wide range of task-relevant changes, thus making vast regions in input space vulnerable to adversarial attacks. After identifying this excessive invariance, we propose the usage of bijective deep networks to enable access to all variations. We introduce metameric sampling as an analytic attack for these networks, requiring no optimization, and show that it uncovers large subspaces of misclassified inputs. Then we apply these networks to MNIST and ImageNet and show that one can manipulate the class-specific content of almost any image without changing the hidden activations. Further, we extend the standard cross-entropy loss to strengthen the model against such manipulations via an information-theoretic analysis, providing the first approach tailored explicitly to overcome invariance-based vulnerability. We conclude by empirically illustrating its ability to control undesirable class-specific invariance, showing promise to overcome one major cause for adversarial examples.