 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Text GANs as Language Models
Paper and Code
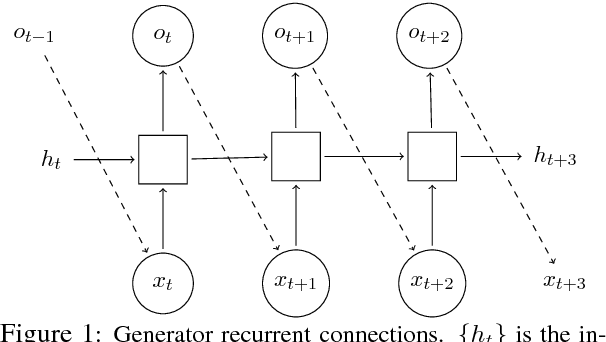


Generative Adversarial Networks (GANs) are a promising approach for text generation that, unlike traditional language models (LM), does not suffer from the problem of "exposure bias". However, A major hurdle for understanding the potential of GANs for text generation is the lack of a clear evaluation metric. In this work, we propose to approximate the distribution of text generated by a GAN, which permits evaluating them with traditional probability-based LM metrics. We apply our approximation procedure on several GAN-based models and show that they currently perform substantially worse than state-of-the-art LMs. Our evaluation procedure promotes better understanding of the relation between GANs and LMs, and can accelerate progress in GAN-based text generation.