 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Superhuman Models with Consistency Checks
Paper and Code
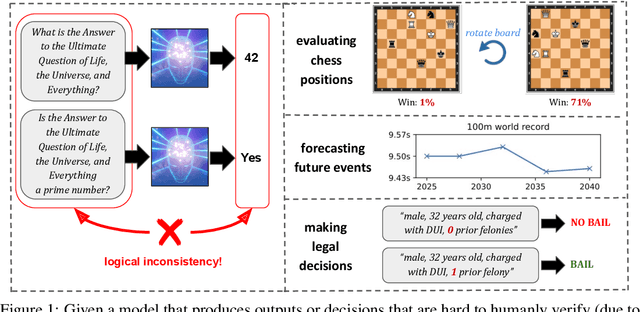
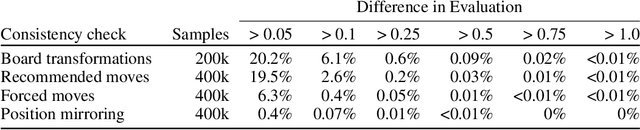
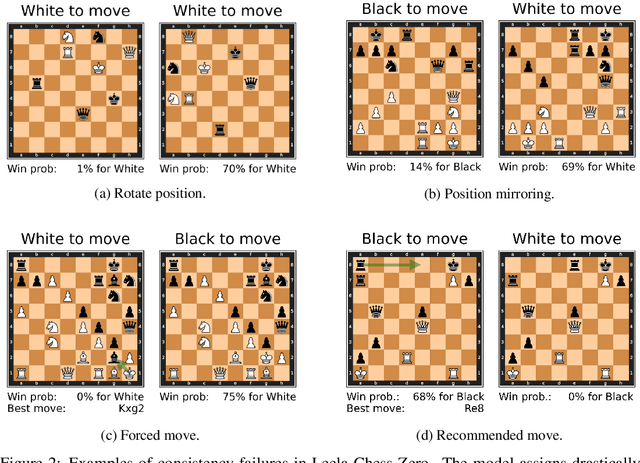
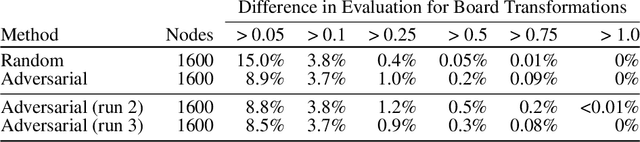
If machine learning models were to achieve superhuman abilities at various reasoning or decision-making tasks, how would we go about evaluating such models, given that humans would necessarily be poor proxies for ground truth? In this paper, we propose a framework for evaluating superhuman models via consistency checks. Our premise is that while the correctness of superhuman decisions may be impossible to evaluate, we can still surface mistakes if the model's decisions fail to satisfy certain logical, human-interpretable rules. We instantiate our framework on three tasks where correctness of decisions is hard to evaluate due to either superhuman model abilities, or to otherwise missing ground truth: evaluating chess positions, forecasting future events, and making legal judgments. We show that regardless of a model's (possibly superhuman) performance on these tasks, we can discover logical inconsistencies in decision making. For example: a chess engine assigning opposing valuations to semantically identical boards; GPT-4 forecasting that sports records will evolve non-monotonically over time; or an AI judge assigning bail to a defendant only after we add a felony to their criminal record.