 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Probabilistic Inference in Deep Learning: Beyond Marginal Predictions
Paper and Code
Jul 20, 2021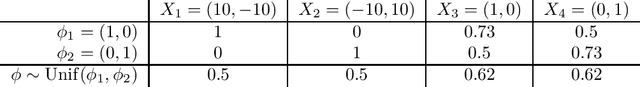
A fundamental challenge for any intelligent system is prediction: given some inputs $X_1,..,X_\tau$ can you predict outcomes $Y_1,.., Y_\tau$. The KL divergence $\mathbf{d}_{\mathrm{KL}}$ provides a natural measure of prediction quality, but the majority of deep learning research looks only at the marginal predictions per input $X_t$. In this technical report we propose a scoring rule $\mathbf{d}_{\mathrm{KL}}^\tau$, parameterized by $\tau \in \mathcal{N}$ that evaluates the joint predictions at $\tau$ inputs simultaneously. We show that the commonly-used $\tau=1$ can be insufficient to drive good decisions in many settings of interest. We also show that, as $\tau$ grows, performing well according to $\mathbf{d}_{\mathrm{KL}}^\tau$ recovers universal guarantees for any possible decision. Finally, we provide problem-dependent guidance on the scale of $\tau$ for which our score provides sufficient guarantees for good performance.