 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Compositionality in Sentence Embeddings
Paper and Code
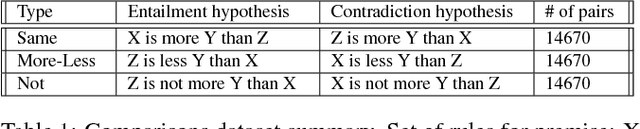
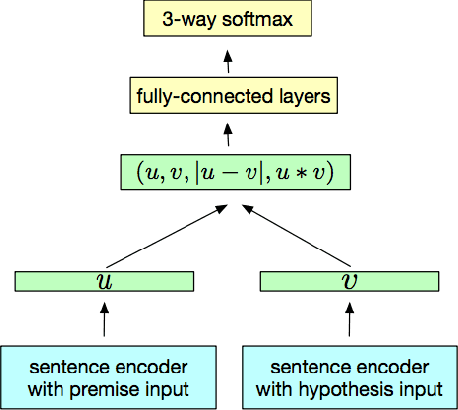
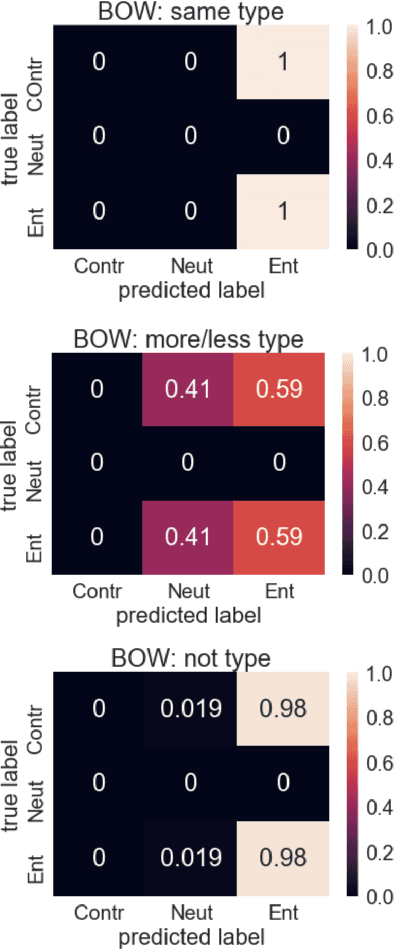
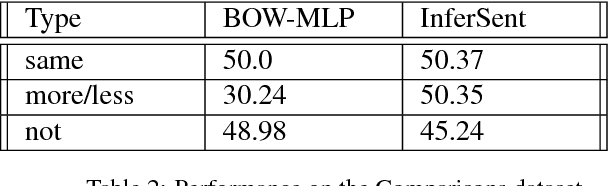
An important challenge for human-like AI is compositional semantics. Recent research has attempted to address this by using deep neural networks to learn vector space embeddings of sentences, which then serve as input to other tasks. We present a new dataset for one such task, `natural language inference' (NLI), that cannot be solved using only word-level knowledge and requires some compositionality. We find that the performance of state of the art sentence embeddings (InferSent; Conneau et al., 2017) on our new dataset is poor. We analyze the decision rules learned by InferSent and find that they are consistent with simple heuristics that are ecologically valid in its training dataset. Further, we find that augmenting training with our dataset improves test performance on our dataset without loss of performance on the original training dataset. This highlights the importance of structured datasets in better understanding and improving AI systems.