 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Combinatorial Generalization in Variational Autoencoders
Paper and Code
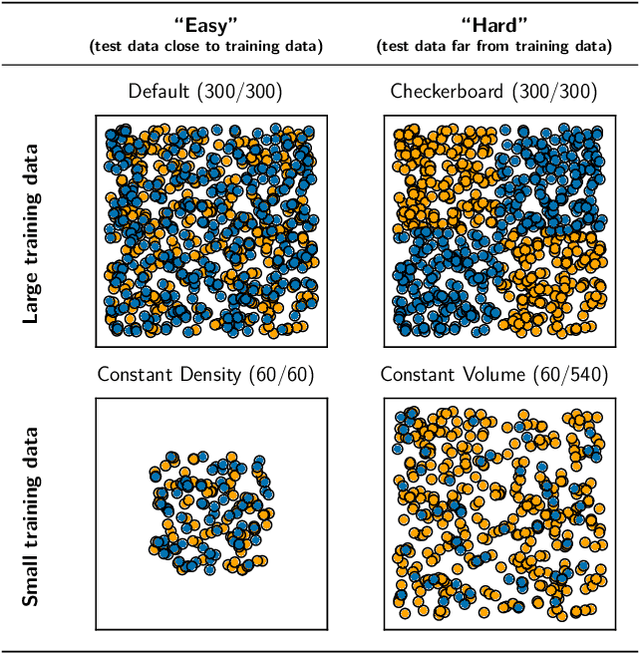
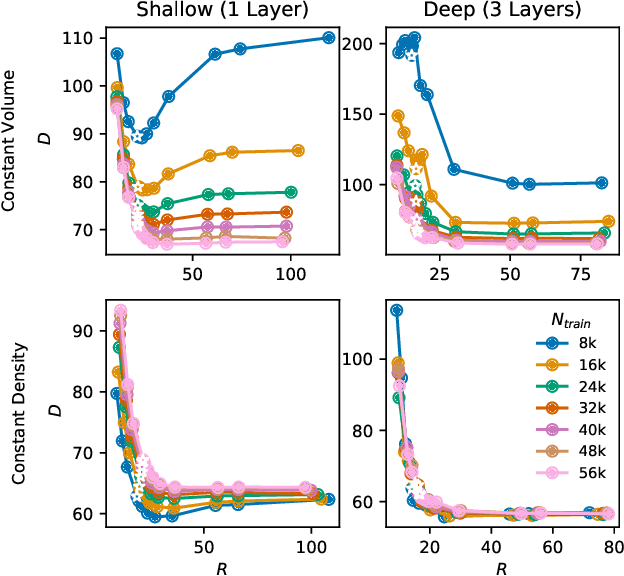
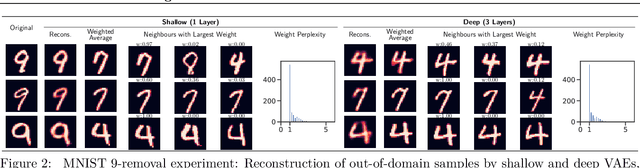

We evaluate the ability of variational autoencoders to generalize to unseen examples in domains with a large combinatorial space of feature values. Our experiments systematically evaluate the effect of network width, depth, regularization, and the typical distance between the training and test examples. Increasing network capacity benefits generalization in easy problems, where test-set examples are similar to training examples. In more difficult problems, increasing capacity deteriorates generalization when optimizing the standard VAE objective, but once again improves generalization when we decrease the KL regularization. Our results establish that interplay between model capacity and KL regularization is not clear cut; we need to take the typical distance between train and test examples into account when evaluating generalization.