 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvalAttAI: A Holistic Approach to Evaluating Attribution Maps in Robust and Non-Robust Models
Paper and Code
Mar 15, 2023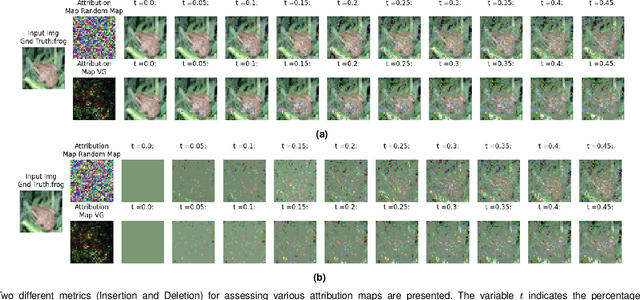
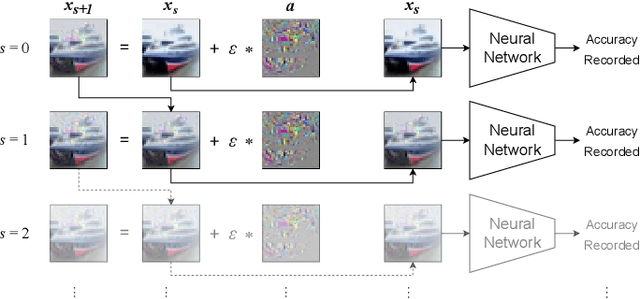

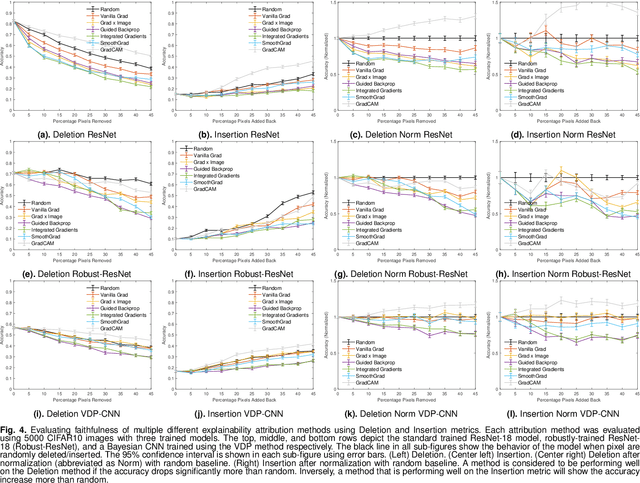
The expansion of explainable artificial intelligence as a field of research has generated numerous methods of visualizing and understanding the black box of a machine learning model. Attribution maps are generally used to highlight the parts of the input image that influence the model to make a specific decision. On the other hand, the robustness of machine learning models to natural noise and adversarial attacks is also being actively explored. This paper focuses on evaluating methods of attribution mapping to find whether robust neural networks are more explainable. We explore this problem within the application of classification for medical imaging. Explainability research is at an impasse. There are many methods of attribution mapping, but no current consensus on how to evaluate them and determine the ones that are the best. Our experiments on multiple datasets (natural and medical imaging) and various attribution methods reveal that two popular evaluation metrics, Deletion and Insertion, have inherent limitations and yield contradictory results. We propose a new explainability faithfulness metric (called EvalAttAI) that addresses the limitations of prior metrics. Using our novel evaluation, we found that Bayesian deep neural networks using the Variational Density Propagation technique were consistently more explainable when used with the best performing attribution method, the Vanilla Gradient. However, in general, various types of robust neural networks may not be more explainable, despite these models producing more visually plausible attribution maps.