 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating and Penalizing Induced Preference Shifts in Recommender Systems
Paper and Code
Apr 25, 2022

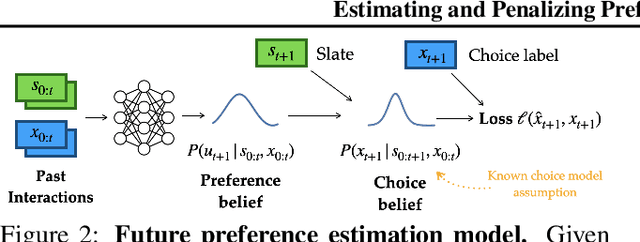

The content that a recommender system (RS) shows to users influences them. Therefore, when choosing which recommender to deploy, one is implicitly also choosing to induce specific internal states in users. Even more, systems trained via long-horizon optimization will have direct incentives to manipulate users, e.g. shift their preferences so they are easier to satisfy. In this work we focus on induced preference shifts in users. We argue that - before deployment - system designers should: estimate the shifts a recommender would induce; evaluate whether such shifts would be undesirable; and even actively optimize to avoid problematic shifts. These steps involve two challenging ingredients: estimation requires anticipating how hypothetical policies would influence user preferences if deployed - we do this by using historical user interaction data to train predictive user model which implicitly contains their preference dynamics; evaluation and optimization additionally require metrics to assess whether such influences are manipulative or otherwise unwanted - we use the notion of "safe shifts", that define a trust region within which behavior is safe. In simulated experiments, we show that our learned preference dynamics model is effective in estimating user preferences and how they would respond to new recommenders. Additionally, we show that recommenders that optimize for staying in the trust region can avoid manipulative behaviors while still generating engagement.