 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating and Maximizing Mutual Information for Knowledge Distillation
Paper and Code
Oct 29, 2021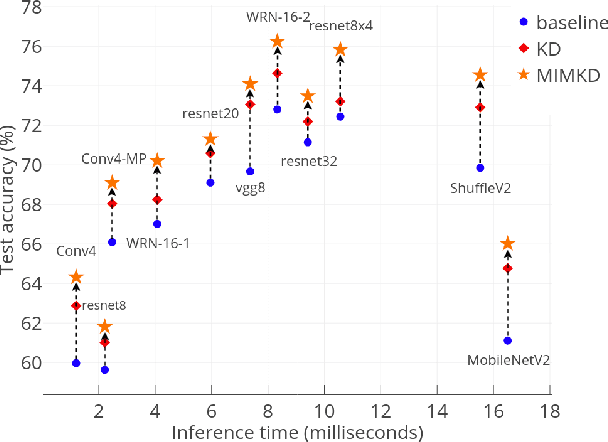
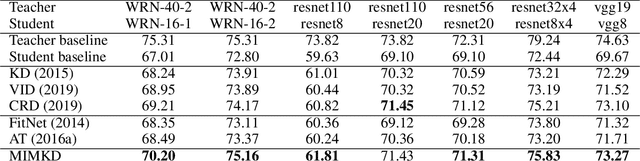
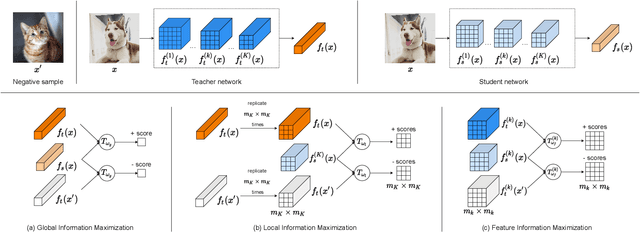
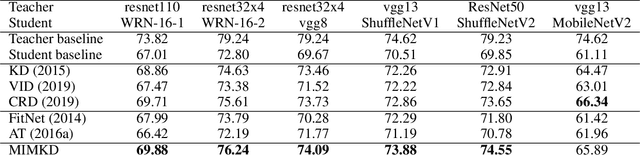
Knowledge distillation is a widely used general technique to transfer knowledge from a teacher network to a student network. In this work, we propose Mutual Information Maximization Knowledge Distillation (MIMKD). Our method uses a contrastive objective to simultaneously estimate and maximize a lower bound on the mutual information between intermediate and global feature representations from the teacher and the student networks. Our method is flexible, as the proposed mutual information maximization does not impose significant constraints on the structure of the intermediate features of the networks. As such, we can distill knowledge from arbitrary teachers to arbitrary students. Our empirical results show that our method outperforms competing approaches across a wide range of student-teacher pairs with different capacities, with different architectures, and when student networks are with extremely low capacity. We are able to obtain 74.55% accuracy on CIFAR100 with a ShufflenetV2 from a baseline accuracy of 69.8% by distilling knowledge from ResNet50.