 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeError-controlled non-additive interaction discovery in machine learning models
Paper and Code
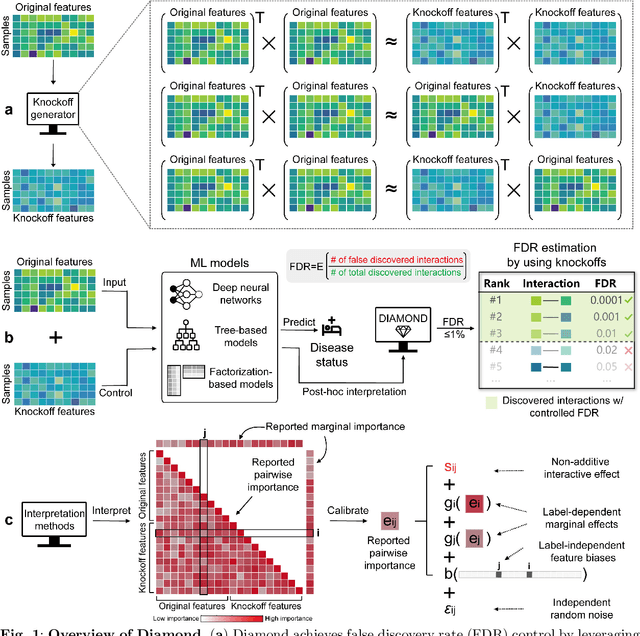
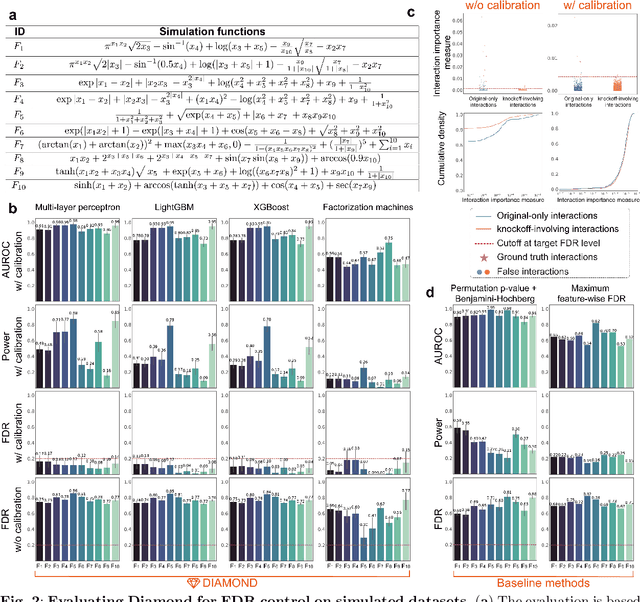
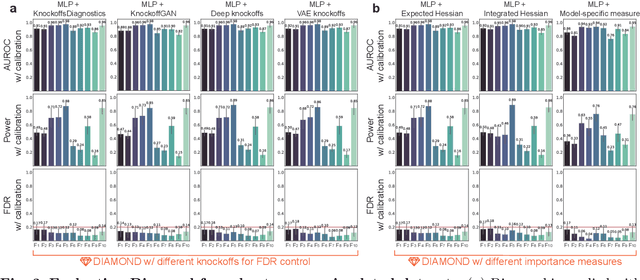
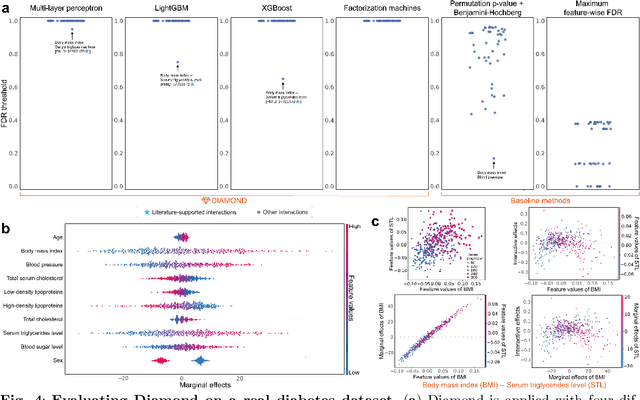
Machine learning (ML) models are powerful tools for detecting complex patterns within data, yet their "black box" nature limits their interpretability, hindering their use in critical domains like healthcare and finance. To address this challenge, interpretable ML methods have been developed to explain how features influence model predictions. However, these methods often focus on univariate feature importance, overlooking the complex interactions between features that ML models are capable of capturing. Recognizing this limitation, recent efforts have aimed to extend these methods to discover feature interactions, but existing approaches struggle with robustness and error control, especially under data perturbations. In this study, we introduce Diamond, a novel method for trustworthy feature interaction discovery. Diamond uniquely integrates the model-X knockoffs framework to control the false discovery rate (FDR), ensuring that the proportion of falsely discovered interactions remains low. We further address the challenges of using off-the-shelf interaction importance measures by proposing a calibration procedure that refines these measures to maintain the desired FDR. Diamond's applicability spans a wide range of ML models, including deep neural networks, tree-based models, and factorization-based models. Our empirical evaluations on both simulated and real datasets across various biomedical studies demonstrate Diamond's utility in enabling more reliable data-driven scientific discoveries. This method represents a significant step forward in the deployment of ML models for scientific innovation and hypothesis generation.