 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 2.0: A Continual Pre-training Framework for Language Understanding
Paper and Code


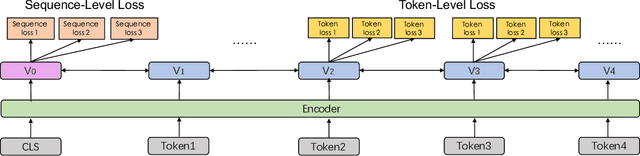

Recently, pre-trained models have achieved state-of-the-art results in various language understanding tasks, which indicates that pre-training on large-scale corpora may play a crucial role in natural language processing. Current pre-training procedures usually focus on training the model with several simple tasks to grasp the co-occurrence of words or sentences. However, besides co-occurring, there exists other valuable lexical, syntactic and semantic information in training corpora, such as named entity, semantic closeness and discourse relations. In order to extract to the fullest extent, the lexical, syntactic and semantic information from training corpora, we propose a continual pre-training framework named ERNIE 2.0 which builds and learns incrementally pre-training tasks through constant multi-task learning. Experimental results demonstrate that ERNIE 2.0 outperforms BERT and XLNet on 16 tasks including English tasks on GLUE benchmarks and several common tasks in Chinese. The source codes and pre-trained models have been released at https://github.com/PaddlePaddle/ERNIE.