 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnumeration of Distinct Support Vectors for Interactive Decision Making
Paper and Code
Jun 05, 2019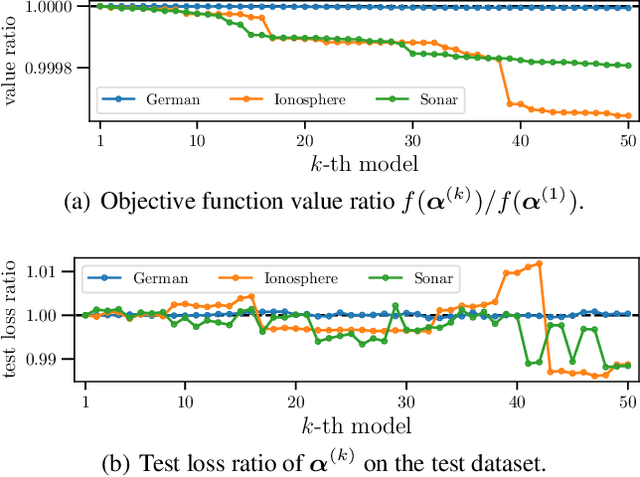
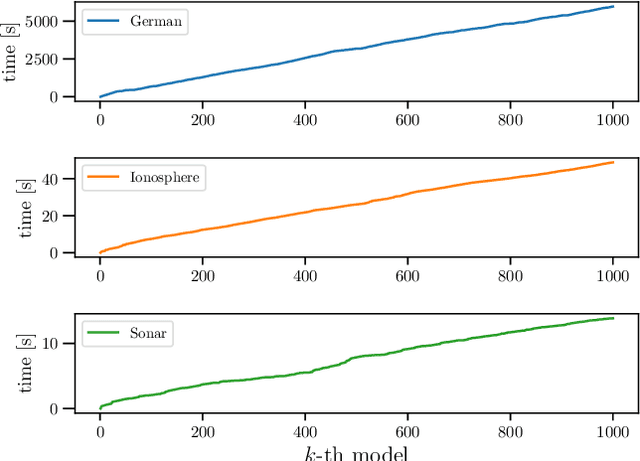
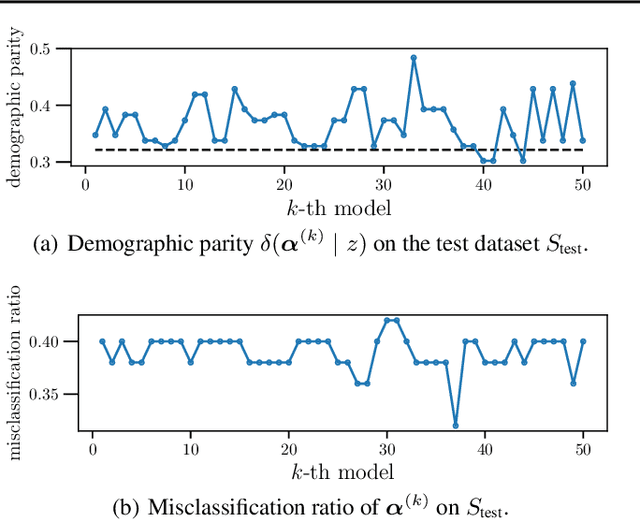
In conventional prediction tasks, a machine learning algorithm outputs a single best model that globally optimizes its objective function, which typically is accuracy. Therefore, users cannot access the other models explicitly. In contrast to this, multiple model enumeration attracts increasing interests in non-standard machine learning applications where other criteria, e.g., interpretability or fairness, than accuracy are main concern and a user may want to access more than one non-optimal, but suitable models. In this paper, we propose a K-best model enumeration algorithm for Support Vector Machines (SVM) that given a dataset S and an integer K>0, enumerates the K-best models on S with distinct support vectors in the descending order of the objective function values in the dual SVM problem. Based on analysis of the lattice structure of support vectors, our algorithm efficiently finds the next best model with small latency. This is useful in supporting users's interactive examination of their requirements on enumerated models. By experiments on real datasets, we evaluated the efficiency and usefulness of our algorithm.