 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy Rate Estimation for Markov Chains with Large State Space
Paper and Code
Sep 24, 2018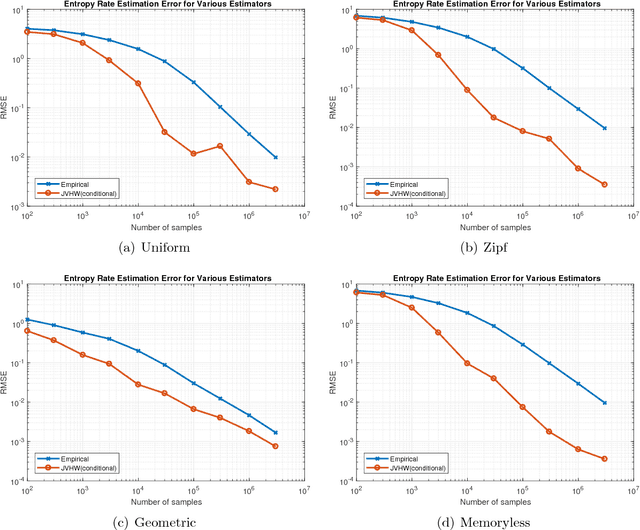
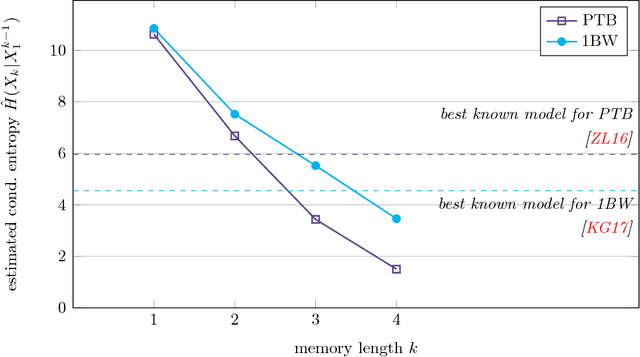
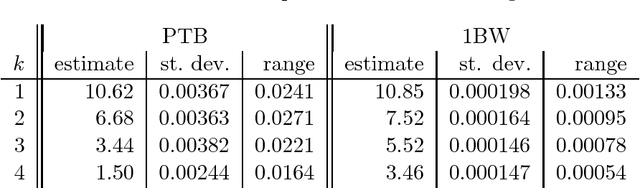
Estimating the entropy based on data is one of the prototypical problems in distribution property testing and estimation. For estimating the Shannon entropy of a distribution on $S$ elements with independent samples, [Paninski2004] showed that the sample complexity is sublinear in $S$, and [Valiant--Valiant2011] showed that consistent estimation of Shannon entropy is possible if and only if the sample size $n$ far exceeds $\frac{S}{\log S}$. In this paper we consider the problem of estimating the entropy rate of a stationary reversible Markov chain with $S$ states from a sample path of $n$ observations. We show that: (1) As long as the Markov chain mixes not too slowly, i.e., the relaxation time is at most $O(\frac{S}{\ln^3 S})$, consistent estimation is achievable when $n \gg \frac{S^2}{\log S}$. (2) As long as the Markov chain has some slight dependency, i.e., the relaxation time is at least $1+\Omega(\frac{\ln^2 S}{\sqrt{S}})$, consistent estimation is impossible when $n \lesssim \frac{S^2}{\log S}$. Under both assumptions, the optimal estimation accuracy is shown to be $\Theta(\frac{S^2}{n \log S})$. In comparison, the empirical entropy rate requires at least $\Omega(S^2)$ samples to be consistent, even when the Markov chain is memoryless. In addition to synthetic experiments, we also apply the estimators that achieve the optimal sample complexity to estimate the entropy rate of the English language in the Penn Treebank and the Google One Billion Words corpora, which provides a natural benchmark for language modeling and relates it directly to the widely used perplexity measure.