 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble feature selection with data-driven thresholding for Alzheimer's disease biomarker discovery
Paper and Code
Jul 05, 2022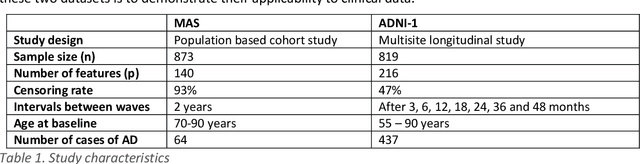

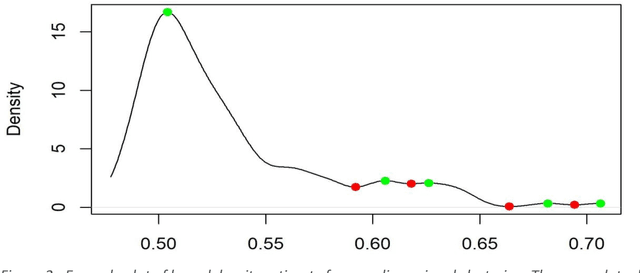
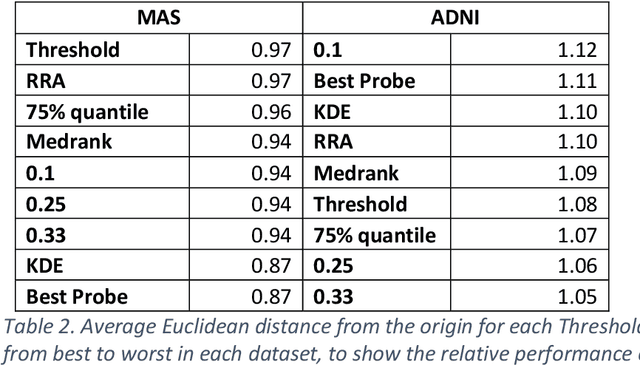
Healthcare datasets present many challenges to both machine learning and statistics as their data are typically heterogeneous, censored, high-dimensional and have missing information. Feature selection is often used to identify the important features but can produce unstable results when applied to high-dimensional data, selecting a different set of features on each iteration. The stability of feature selection can be improved with the use of feature selection ensembles, which aggregate the results of multiple base feature selectors. A threshold must be applied to the final aggregated feature set to separate the relevant features from the redundant ones. A fixed threshold, which is typically applied, offers no guarantee that the final set of selected features contains only relevant features. This work develops several data-driven thresholds to automatically identify the relevant features in an ensemble feature selector and evaluates their predictive accuracy and stability. To demonstrate the applicability of these methods to clinical data, they are applied to data from two real-world Alzheimer's disease (AD) studies. AD is a progressive neurodegenerative disease with no known cure, that begins at least 2-3 decades before overt symptoms appear, presenting an opportunity for researchers to identify early biomarkers that might identify patients at risk of developing AD. Features identified by applying these methods to both datasets reflect current findings in the AD literature.