 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble feature selection with clustering for analysis of high-dimensional, correlated clinical data in the search for Alzheimer's disease biomarkers
Paper and Code
Jul 06, 2022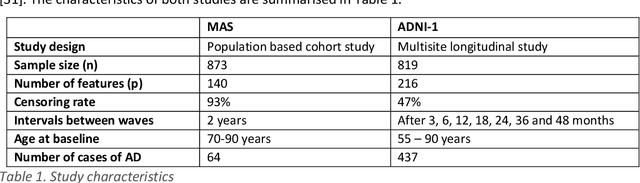
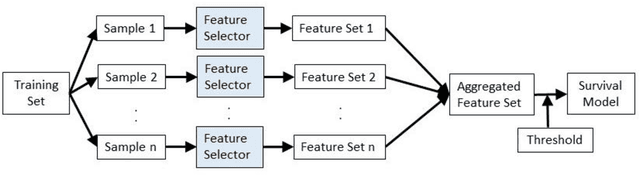
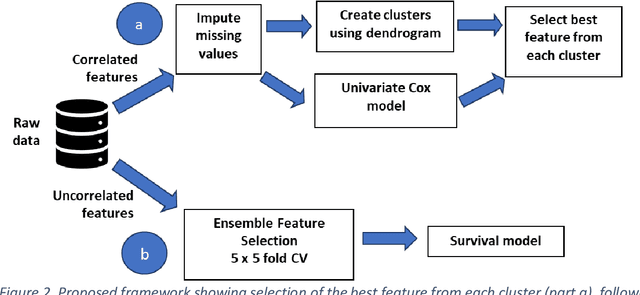
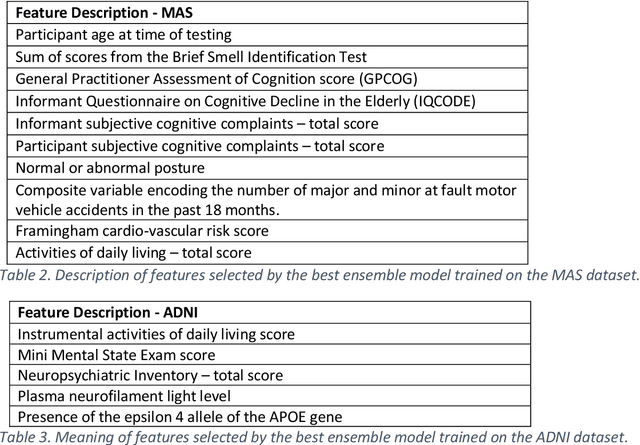
Healthcare datasets often contain groups of highly correlated features, such as features from the same biological system. When feature selection is applied to these datasets to identify the most important features, the biases inherent in some multivariate feature selectors due to correlated features make it difficult for these methods to distinguish between the important and irrelevant features and the results of the feature selection process can be unstable. Feature selection ensembles, which aggregate the results of multiple individual base feature selectors, have been investigated as a means of stabilising feature selection results, but do not address the problem of correlated features. We present a novel framework to create feature selection ensembles from multivariate feature selectors while taking into account the biases produced by groups of correlated features, using agglomerative hierarchical clustering in a pre-processing step. These methods were applied to two real-world datasets from studies of Alzheimer's disease (AD), a progressive neurodegenerative disease that has no cure and is not yet fully understood. Our results show a marked improvement in the stability of features selected over the models without clustering, and the features selected by these models are in keeping with the findings in the AD literature.