 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble Distribution Distillation
Paper and Code
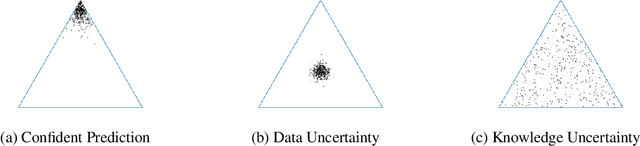
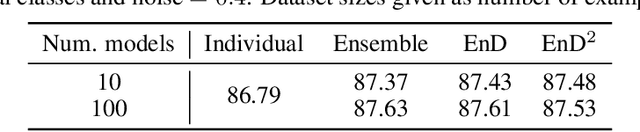
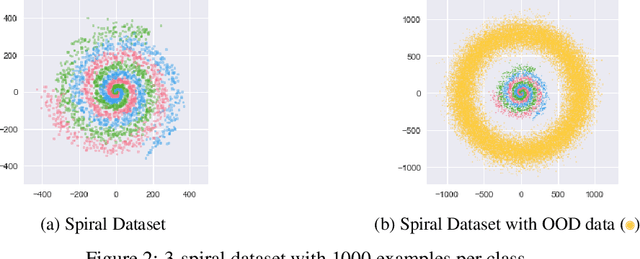

Ensembles of models often yield improvements in system performance. They have also been empirically shown to yield robust measures of uncertainty, and are capable of distinguishing between different forms of uncertainty. However, ensembles come at a computational and memory cost which may be prohibitive for many applications. There has been significant work done on the distillation of an ensemble into a single model. Such approaches decrease computational cost and allow a single model to achieve an accuracy comparable to that of an ensemble. However, information about the diversity of the ensemble, which can yield estimates of different forms of uncertainty, is lost. Recently, a new class of models called Prior Networks has been proposed, which allows a single neural network to explicitly model a distribution over output distributions. In this work, Ensemble Distillation and Prior Networks are combined to yield a novel approach called Ensemble Distribution Distillation (EnD$^2$), in which the distribution of an ensemble is distilled into a single Prior Network. This enables a single model to retain both the improved classification performance as well as measures of diversity of the ensemble. The properties of EnD$^2$ have been investigated on both an artificial dataset, and on the CIFAR-10 dataset, where it is shown that EnD$^2$ can approach the performance of an ensemble, and outperforms both standard DNNs and standard Ensemble Distillation.