 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Variational Autoencoders with Smooth Robust Latent Encoding
Paper and Code
Apr 24, 2025
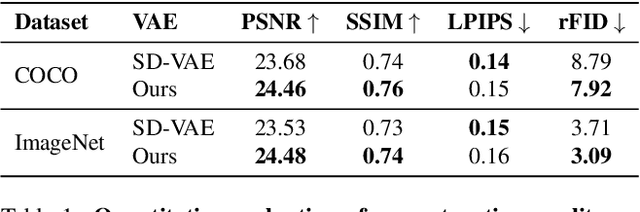
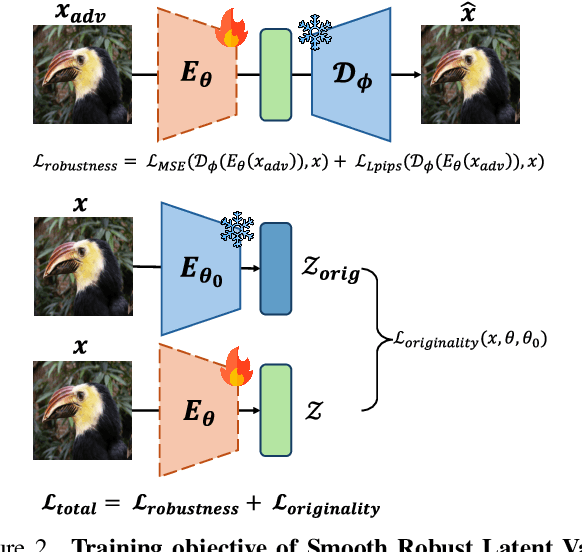
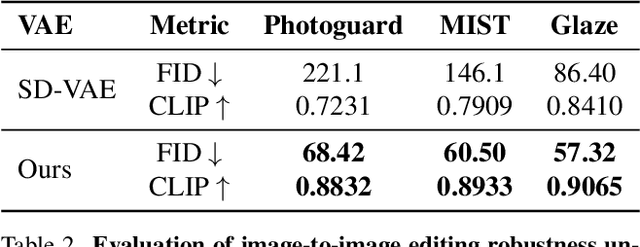
Variational Autoencoders (VAEs) have played a key role in scaling up diffusion-based generative models, as in Stable Diffusion, yet questions regarding their robustness remain largely underexplored. Although adversarial training has been an established technique for enhancing robustness in predictive models, it has been overlooked for generative models due to concerns about potential fidelity degradation by the nature of trade-offs between performance and robustness. In this work, we challenge this presumption, introducing Smooth Robust Latent VAE (SRL-VAE), a novel adversarial training framework that boosts both generation quality and robustness. In contrast to conventional adversarial training, which focuses on robustness only, our approach smooths the latent space via adversarial perturbations, promoting more generalizable representations while regularizing with originality representation to sustain original fidelity. Applied as a post-training step on pre-trained VAEs, SRL-VAE improves image robustness and fidelity with minimal computational overhead. Experiments show that SRL-VAE improves both generation quality, in image reconstruction and text-guided image editing, and robustness, against Nightshade attacks and image editing attacks. These results establish a new paradigm, showing that adversarial training, once thought to be detrimental to generative models, can instead enhance both fidelity and robustness.