 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced sampling of robust molecular datasets with uncertainty-based collective variables
Paper and Code
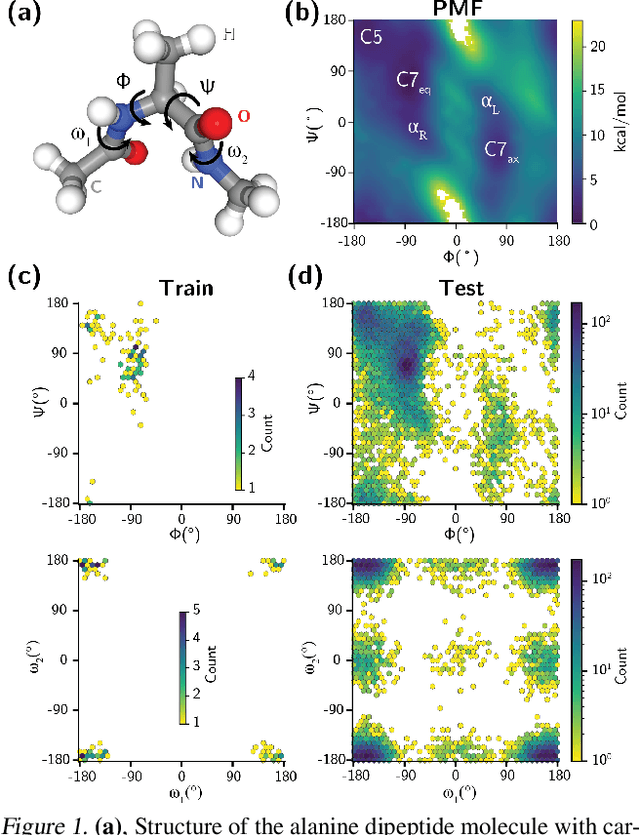
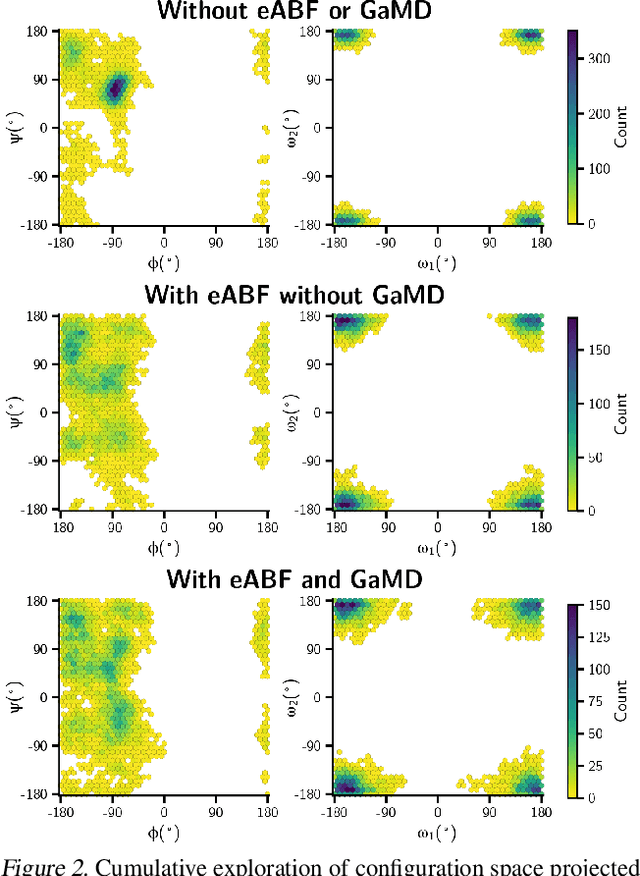
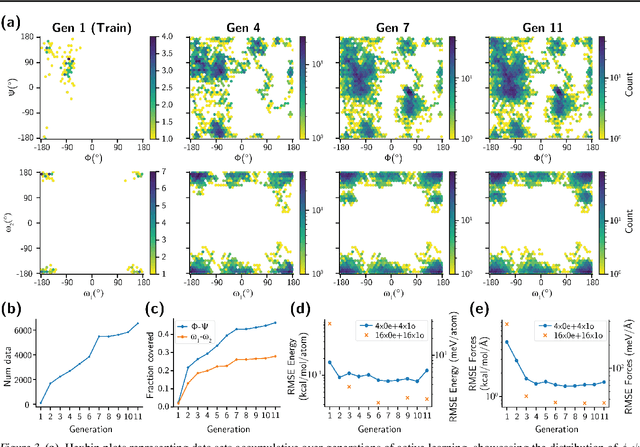
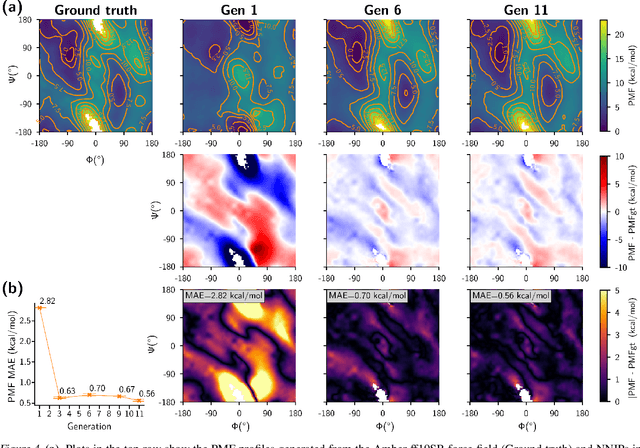
Generating a data set that is representative of the accessible configuration space of a molecular system is crucial for the robustness of machine learned interatomic potentials (MLIP). However, the complexity of molecular systems, characterized by intricate potential energy surfaces (PESs) with numerous local minima and energy barriers, presents a significant challenge. Traditional methods of data generation, such as random sampling or exhaustive exploration, are either intractable or may not capture rare, but highly informative configurations. In this study, we propose a method that leverages uncertainty as the collective variable (CV) to guide the acquisition of chemically-relevant data points, focusing on regions of the configuration space where ML model predictions are most uncertain. This approach employs a Gaussian Mixture Model-based uncertainty metric from a single model as the CV for biased molecular dynamics simulations. The effectiveness of our approach in overcoming energy barriers and exploring unseen energy minima, thereby enhancing the data set in an active learning framework, is demonstrated on the alanine dipeptide benchmark system.