 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Image Classification With Data Augmentation Using Position Coordinates
Paper and Code
Jan 05, 2018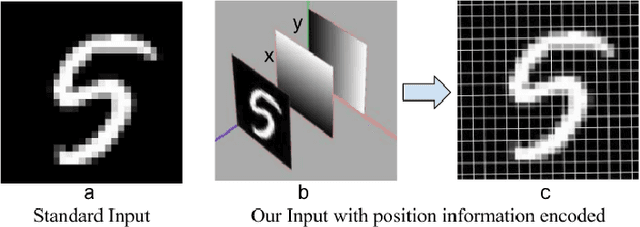
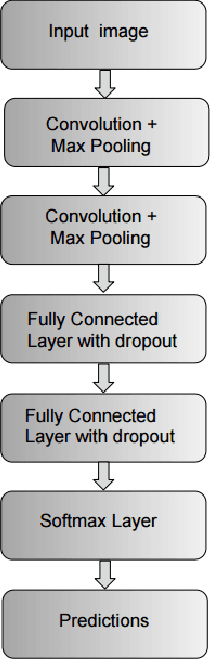

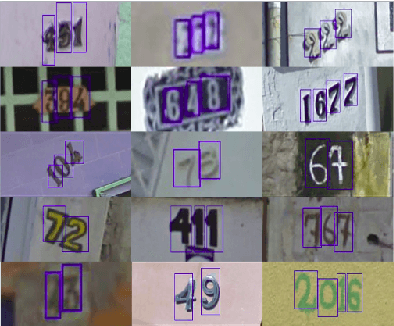
In this paper we propose the use of image pixel position coordinate system to improve image classification accuracy in various applications. Specifically, we hypothesize that the use of pixel coordinates will lead to (a) Resolution invariant performance. Here, by resolution we mean the spacing between the pixels rather than the size of the image matrix. (b) Overall improvement in classification accuracy in comparison with network models trained without local pixel coordinates. This is due to position coordinates enabling the network to learn relationship between parts of objects, mimicking the human vision system. We demonstrate our hypothesis using empirical results and intuitive explanations of the feature maps learnt by deep neural networks. Specifically, our approach showed improvements in MNIST digit classification and beats state of the results on the SVHN database. We also show that the performance of our networks is unaffected despite training the same using blurred images of the MNIST database and predicting on the high resolution database.