 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEndoDAC: Efficient Adapting Foundation Model for Self-Supervised Depth Estimation from Any Endoscopic Camera
Paper and Code
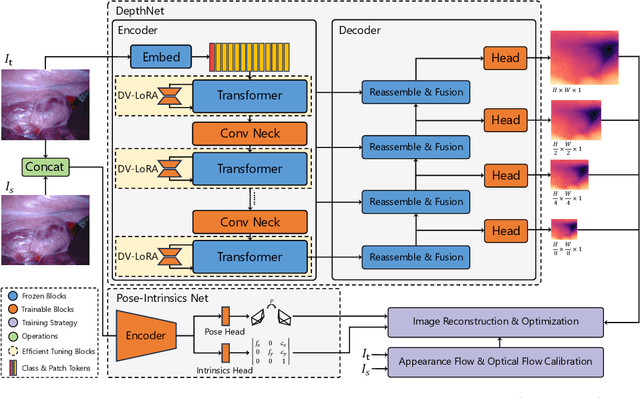
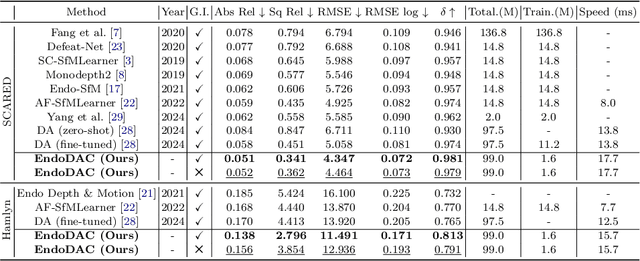
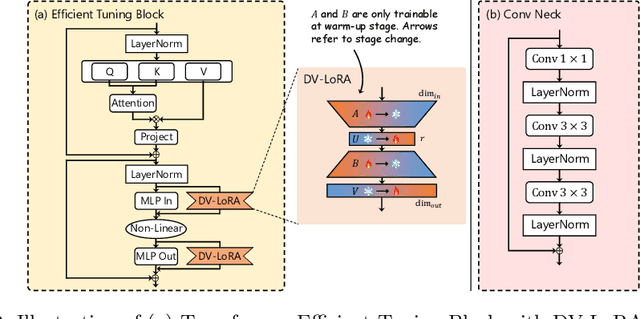
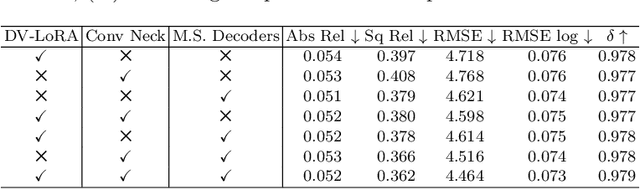
Depth estimation plays a crucial role in various tasks within endoscopic surgery, including navigation, surface reconstruction, and augmented reality visualization. Despite the significant achievements of foundation models in vision tasks, including depth estimation, their direct application to the medical domain often results in suboptimal performance. This highlights the need for efficient adaptation methods to adapt these models to endoscopic depth estimation. We propose Endoscopic Depth Any Camera (EndoDAC) which is an efficient self-supervised depth estimation framework that adapts foundation models to endoscopic scenes. Specifically, we develop the Dynamic Vector-Based Low-Rank Adaptation (DV-LoRA) and employ Convolutional Neck blocks to tailor the foundational model to the surgical domain, utilizing remarkably few trainable parameters. Given that camera information is not always accessible, we also introduce a self-supervised adaptation strategy that estimates camera intrinsics using the pose encoder. Our framework is capable of being trained solely on monocular surgical videos from any camera, ensuring minimal training costs. Experiments demonstrate that our approach obtains superior performance even with fewer training epochs and unaware of the ground truth camera intrinsics. Code is available at https://github.com/BeileiCui/EndoDAC.