 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Transformer Based Model for Image Captioning
Paper and Code
Mar 29, 2022
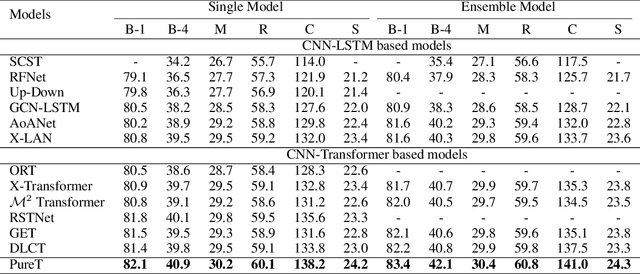
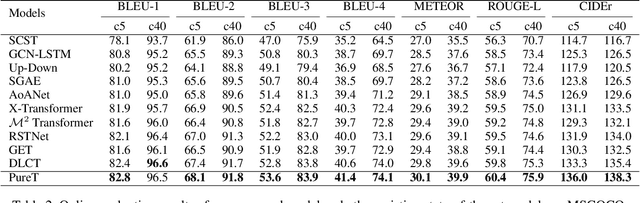
CNN-LSTM based architectures have played an important role in image captioning, but limited by the training efficiency and expression ability, researchers began to explore the CNN-Transformer based models and achieved great success. Meanwhile, almost all recent works adopt Faster R-CNN as the backbone encoder to extract region-level features from given images. However, Faster R-CNN needs a pre-training on an additional dataset, which divides the image captioning task into two stages and limits its potential applications. In this paper, we build a pure Transformer-based model, which integrates image captioning into one stage and realizes end-to-end training. Firstly, we adopt SwinTransformer to replace Faster R-CNN as the backbone encoder to extract grid-level features from given images; Then, referring to Transformer, we build a refining encoder and a decoder. The refining encoder refines the grid features by capturing the intra-relationship between them, and the decoder decodes the refined features into captions word by word. Furthermore, in order to increase the interaction between multi-modal (vision and language) features to enhance the modeling capability, we calculate the mean pooling of grid features as the global feature, then introduce it into refining encoder to refine with grid features together, and add a pre-fusion process of refined global feature and generated words in decoder. To validate the effectiveness of our proposed model, we conduct experiments on MSCOCO dataset. The experimental results compared to existing published works demonstrate that our model achieves new state-of-the-art performances of 138.2% (single model) and 141.0% (ensemble of 4 models) CIDEr scores on `Karpathy' offline test split and 136.0% (c5) and 138.3% (c40) CIDEr scores on the official online test server. Trained models and source code will be released.