 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End QA on COVID-19: Domain Adaptation with Synthetic Training
Paper and Code

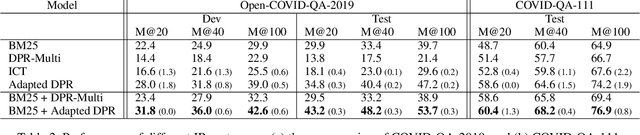


End-to-end question answering (QA) requires both information retrieval (IR) over a large document collection and machine reading comprehension (MRC) on the retrieved passages. Recent work has successfully trained neural IR systems using only supervised question answering (QA) examples from open-domain datasets. However, despite impressive performance on Wikipedia, neural IR lags behind traditional term matching approaches such as BM25 in more specific and specialized target domains such as COVID-19. Furthermore, given little or no labeled data, effective adaptation of QA systems can also be challenging in such target domains. In this work, we explore the application of synthetically generated QA examples to improve performance on closed-domain retrieval and MRC. We combine our neural IR and MRC systems and show significant improvements in end-to-end QA on the CORD-19 collection over a state-of-the-art open-domain QA baseline.