 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end model for named entity recognition from speech without paired training data
Paper and Code
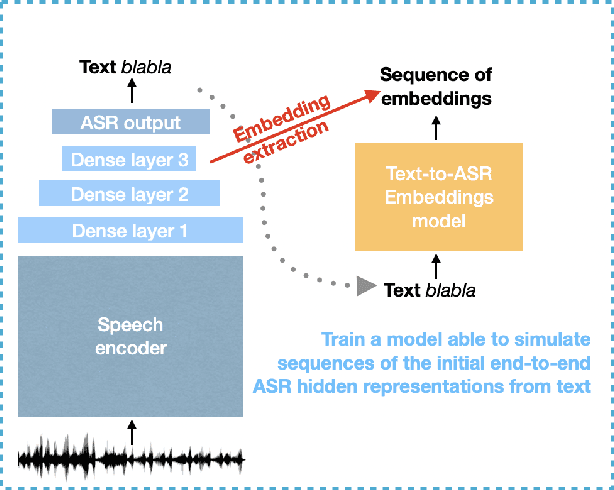
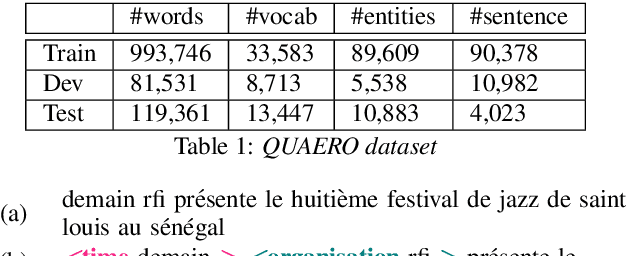
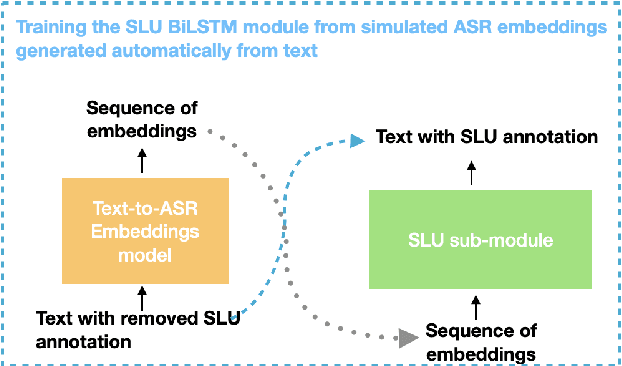

Recent works showed that end-to-end neural approaches tend to become very popular for spoken language understanding (SLU). Through the term end-to-end, one considers the use of a single model optimized to extract semantic information directly from the speech signal. A major issue for such models is the lack of paired audio and textual data with semantic annotation. In this paper, we propose an approach to build an end-to-end neural model to extract semantic information in a scenario in which zero paired audio data is available. Our approach is based on the use of an external model trained to generate a sequence of vectorial representations from text. These representations mimic the hidden representations that could be generated inside an end-to-end automatic speech recognition (ASR) model by processing a speech signal. An SLU neural module is then trained using these representations as input and the annotated text as output. Last, the SLU module replaces the top layers of the ASR model to achieve the construction of the end-to-end model. Our experiments on named entity recognition, carried out on the QUAERO corpus, show that this approach is very promising, getting better results than a comparable cascade approach or than the use of synthetic voices.