 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncoderMI: Membership Inference against Pre-trained Encoders in Contrastive Learning
Paper and Code
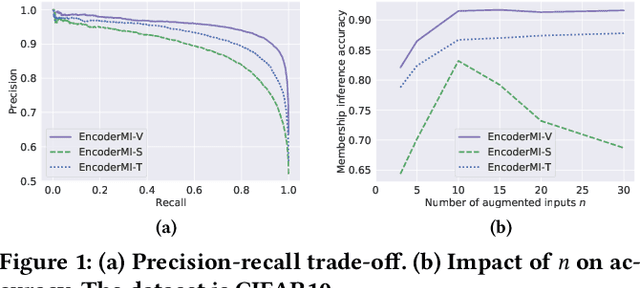
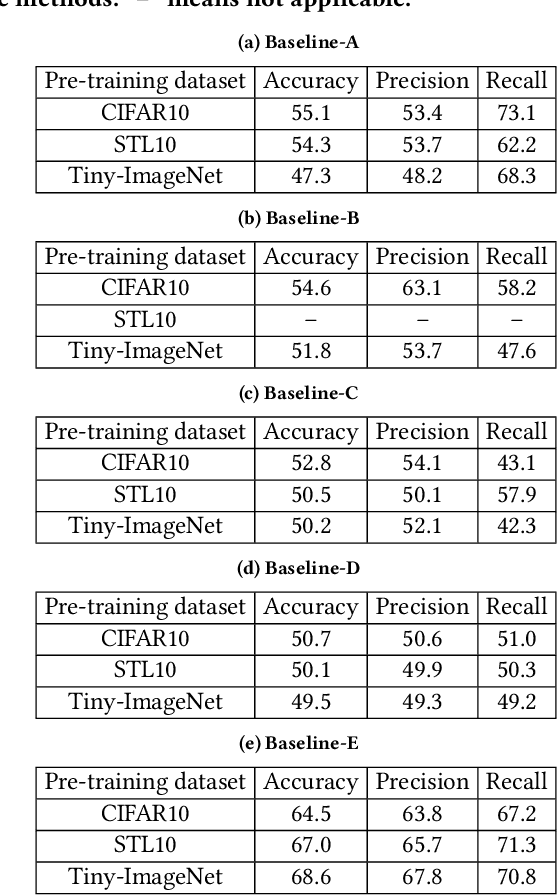
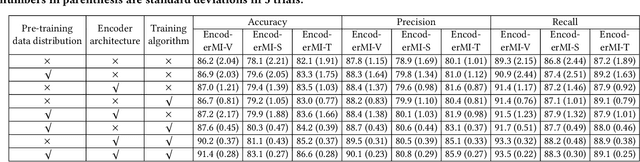
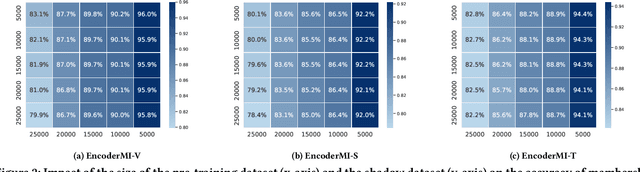
Given a set of unlabeled images or (image, text) pairs, contrastive learning aims to pre-train an image encoder that can be used as a feature extractor for many downstream tasks. In this work, we propose EncoderMI, the first membership inference method against image encoders pre-trained by contrastive learning. In particular, given an input and a black-box access to an image encoder, EncoderMI aims to infer whether the input is in the training dataset of the image encoder. EncoderMI can be used 1) by a data owner to audit whether its (public) data was used to pre-train an image encoder without its authorization or 2) by an attacker to compromise privacy of the training data when it is private/sensitive. Our EncoderMI exploits the overfitting of the image encoder towards its training data. In particular, an overfitted image encoder is more likely to output more (or less) similar feature vectors for two augmented versions of an input in (or not in) its training dataset. We evaluate EncoderMI on image encoders pre-trained on multiple datasets by ourselves as well as the Contrastive Language-Image Pre-training (CLIP) image encoder, which is pre-trained on 400 million (image, text) pairs collected from the Internet and released by OpenAI. Our results show that EncoderMI can achieve high accuracy, precision, and recall. We also explore a countermeasure against EncoderMI via preventing overfitting through early stopping. Our results show that it achieves trade-offs between accuracy of EncoderMI and utility of the image encoder, i.e., it can reduce the accuracy of EncoderMI, but it also incurs classification accuracy loss of the downstream classifiers built based on the image encoder.