 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncoded Hourglass Network for Semantic Segmentation of High Resolution Aerial Imagery
Paper and Code
Oct 30, 2018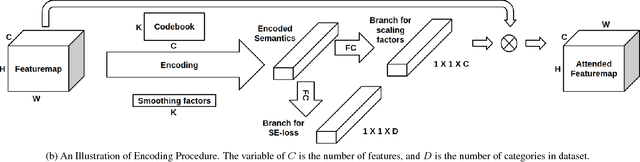
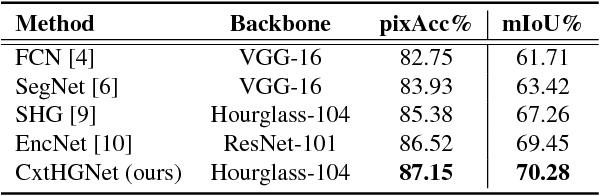
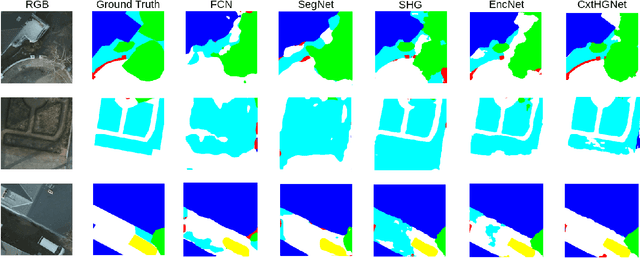
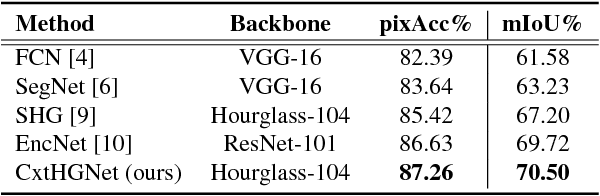
Fully Convolutional Network (FCN) has been widely used in recent work for semantic segmentation of high resolution aerial imagery. However, FCN is poor at extracting multi-scale features and exploiting contextual information. In this paper, we explore stacked encoder-decoder structure which enables repeated bottom-up, top-down inference across various scales and consolidates global and local information of the image. Moreover, we utilize the Context Encoding Module to capture the global contextual semantics of scenes and selectively emphasize or de-emphasize class-dependent featuremaps. Our approach is further enhanced by intermediate supervision on the predictions of multiple decoders and has achieved 87.01% pixel accuracy and 69.78% mIoU on Potsdam test set, which surpasses various baseline models.