 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Long-Term Cooperation in Cross-Silo Federated Learning: A Repeated Game Perspective
Paper and Code
Jun 22, 2021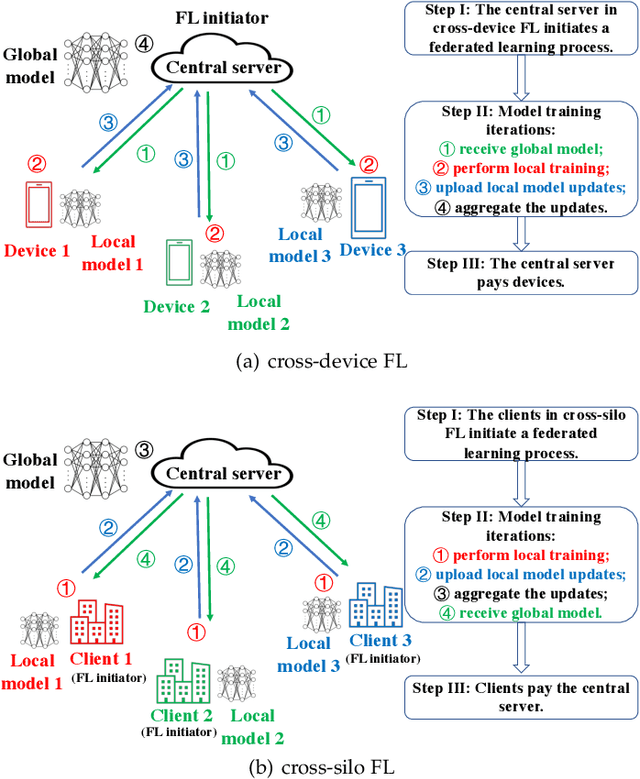
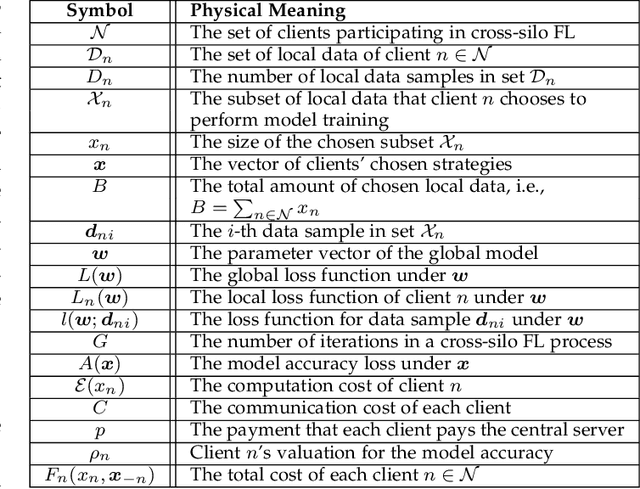

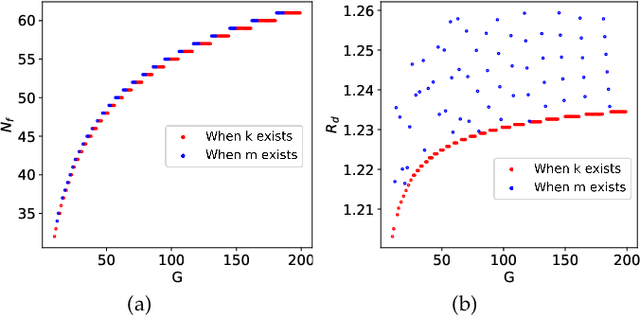
Cross-silo federated learning (FL) is a distributed learning approach where clients train a global model cooperatively while keeping their local data private. Different from cross-device FL, clients in cross-silo FL are usually organizations or companies which may execute multiple cross-silo FL processes repeatedly due to their time-varying local data sets, and aim to optimize their long-term benefits by selfishly choosing their participation levels. While there has been some work on incentivizing clients to join FL, the analysis of the long-term selfish participation behaviors of clients in cross-silo FL remains largely unexplored. In this paper, we analyze the selfish participation behaviors of heterogeneous clients in cross-silo FL. Specifically, we model the long-term selfish participation behaviors of clients as an infinitely repeated game, with the stage game being a selfish participation game in one cross-silo FL process (SPFL). For the stage game SPFL, we derive the unique Nash equilibrium (NE), and propose a distributed algorithm for each client to calculate its equilibrium participation strategy. For the long-term interactions among clients, we derive a cooperative strategy for clients which minimizes the number of free riders while increasing the amount of local data for model training. We show that enforced by a punishment strategy, such a cooperative strategy is a SPNE of the infinitely repeated game, under which some clients who are free riders at the NE of the stage game choose to be (partial) contributors. We further propose an algorithm to calculate the optimal SPNE which minimizes the number of free riders while maximizing the amount of local data for model training. Simulation results show that our proposed cooperative strategy at the optimal SPNE can effectively reduce the number of free riders and increase the amount of local data for model training.