 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Analysis of Model Selection for Heterogenous Causal Effect Estimation
Paper and Code
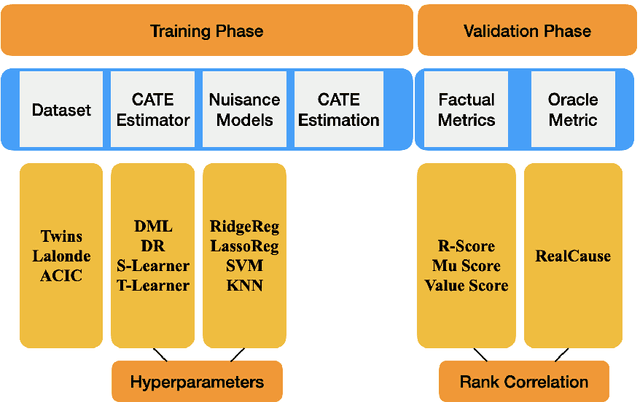
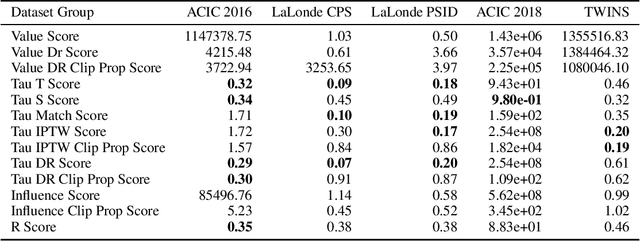
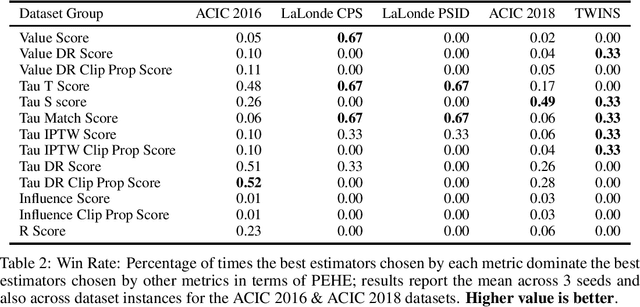
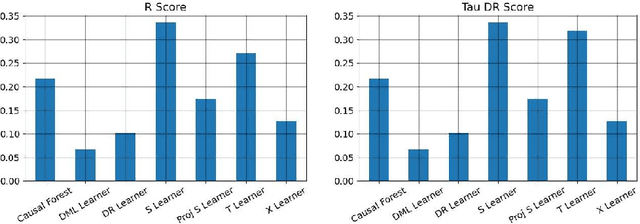
We study the problem of model selection in causal inference, specifically for the case of conditional average treatment effect (CATE) estimation under binary treatments. Unlike model selection in machine learning, we cannot use the technique of cross-validation here as we do not observe the counterfactual potential outcome for any data point. Hence, we need to design model selection techniques that do not explicitly rely on counterfactual data. As an alternative to cross-validation, there have been a variety of proxy metrics proposed in the literature, that depend on auxiliary nuisance models also estimated from the data (propensity score model, outcome regression model). However, the effectiveness of these metrics has only been studied on synthetic datasets as we can observe the counterfactual data for them. We conduct an extensive empirical analysis to judge the performance of these metrics, where we utilize the latest advances in generative modeling to incorporate multiple realistic datasets. We evaluate 9 metrics on 144 datasets for selecting between 415 estimators per dataset, including datasets that closely mimic real-world datasets. Further, we use the latest techniques from AutoML to ensure consistent hyperparameter selection for nuisance models for a fair comparison across metrics.