 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotions Don't Lie: A Deepfake Detection Method using Audio-Visual Affective Cues
Paper and Code
Mar 17, 2020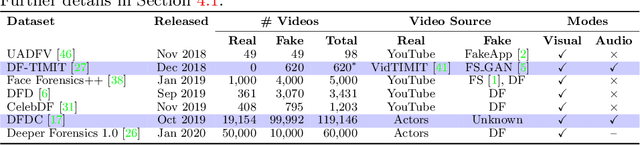
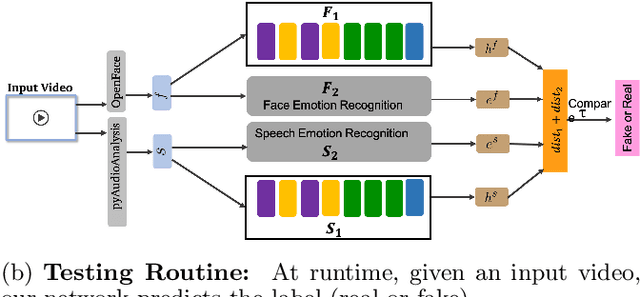
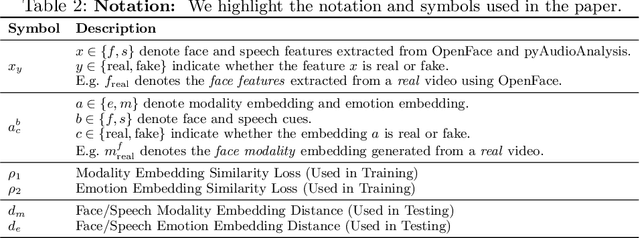

We present a learning-based multimodal method for detecting real and deepfake videos. To maximize information for learning, we extract and analyze the similarity between the two audio and visual modalities from within the same video. Additionally, we extract and compare affective cues corresponding to emotion from the two modalities within a video to infer whether the input video is "real" or "fake". We propose a deep learning network, inspired by the Siamese network architecture and the triplet loss. To validate our model, we report the AUC metric on two large-scale, audio-visual deepfake detection datasets, DeepFake-TIMIT Dataset and DFDC. We compare our approach with several SOTA deepfake detection methods and report per-video AUC of 84.4% on the DFDC and 96.6% on the DF-TIMIT datasets, respectively.