 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodiment-Agnostic Navigation Policy Trained with Visual Demonstrations
Paper and Code

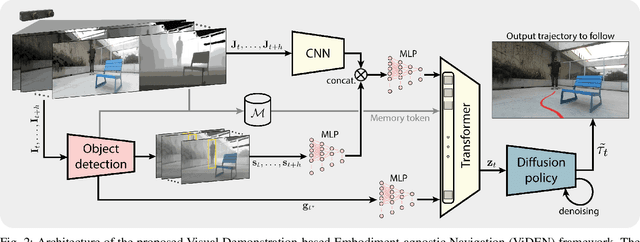


Learning to navigate in unstructured environments is a challenging task for robots. While reinforcement learning can be effective, it often requires extensive data collection and can pose risk. Learning from expert demonstrations, on the other hand, offers a more efficient approach. However, many existing methods rely on specific robot embodiments, pre-specified target images and require large datasets. We propose the Visual Demonstration-based Embodiment-agnostic Navigation (ViDEN) framework, a novel framework that leverages visual demonstrations to train embodiment-agnostic navigation policies. ViDEN utilizes depth images to reduce input dimensionality and relies on relative target positions, making it more adaptable to diverse environments. By training a diffusion-based policy on task-centric and embodiment-agnostic demonstrations, ViDEN can generate collision-free and adaptive trajectories in real-time. Our experiments on human reaching and tracking demonstrate that ViDEN outperforms existing methods, requiring a small amount of data and achieving superior performance in various indoor and outdoor navigation scenarios. Project website: https://nimicurtis.github.io/ViDEN/.