 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding Multimodal Relational Data for Knowledge Base Completion
Paper and Code

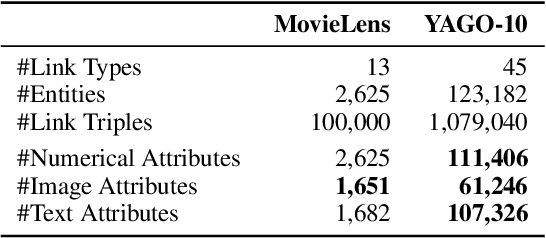


Representing entities and relations in an embedding space is a well-studied approach for machine learning on relational data. Existing approaches, however, primarily focus on simple link structure between a finite set of entities, ignoring the variety of data types that are often used in knowledge bases, such as text, images, and numerical values. In this paper, we propose multimodal knowledge base embeddings (MKBE) that use different neural encoders for this variety of observed data, and combine them with existing relational models to learn embeddings of the entities and multimodal data. Further, using these learned embedings and different neural decoders, we introduce a novel multimodal imputation model to generate missing multimodal values, like text and images, from information in the knowledge base. We enrich existing relational datasets to create two novel benchmarks that contain additional information such as textual descriptions and images of the original entities. We demonstrate that our models utilize this additional information effectively to provide more accurate link prediction, achieving state-of-the-art results with a considerable gap of 5-7% over existing methods. Further, we evaluate the quality of our generated multimodal values via a user study. We have release the datasets and the open-source implementation of our models at https://github.com/pouyapez/mkbe