 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding-Enhanced Giza++: Improving Alignment in Low- and High- Resource Scenarios Using Embedding Space Geometry
Paper and Code
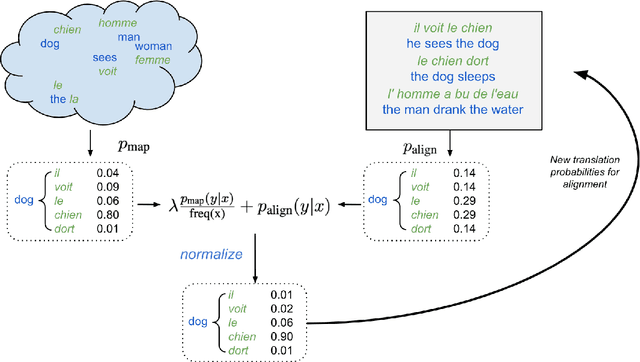
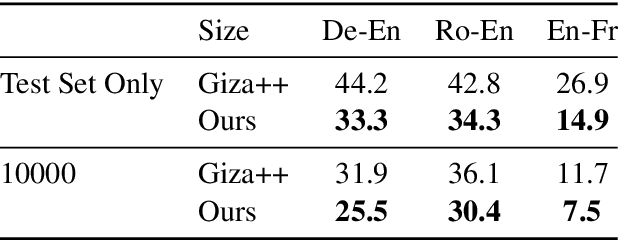
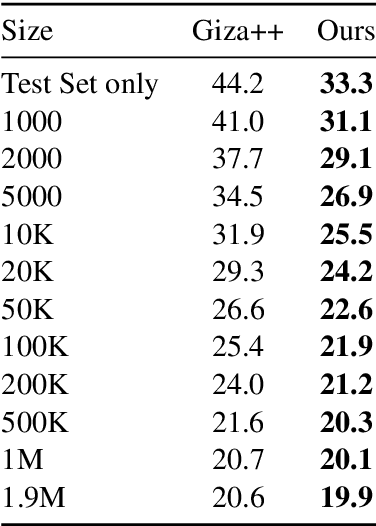
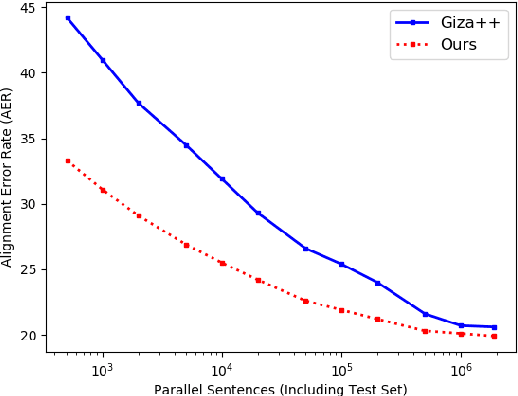
A popular natural language processing task decades ago, word alignment has been dominated until recently by GIZA++, a statistical method based on the 30-year-old IBM models. Though recent years have finally seen Giza++ performance bested, the new methods primarily rely on large machine translation models, massively multilingual language models, or supervision from Giza++ alignments itself. We introduce Embedding-Enhanced Giza++, and outperform Giza++ without any of the aforementioned factors. Taking advantage of monolingual embedding space geometry of the source and target language only, we exceed Giza++'s performance in every tested scenario for three languages. In the lowest-resource scenario of only 500 lines of bitext, we improve performance over Giza++ by 10.9 AER. Our method scales monotonically outperforming Giza++ for all tested scenarios between 500 and 1.9 million lines of bitext. Our code will be made publicly available.