 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELSA: Partial Weight Freezing for Overhead-Free Sparse Network Deployment
Paper and Code
Dec 17, 2023
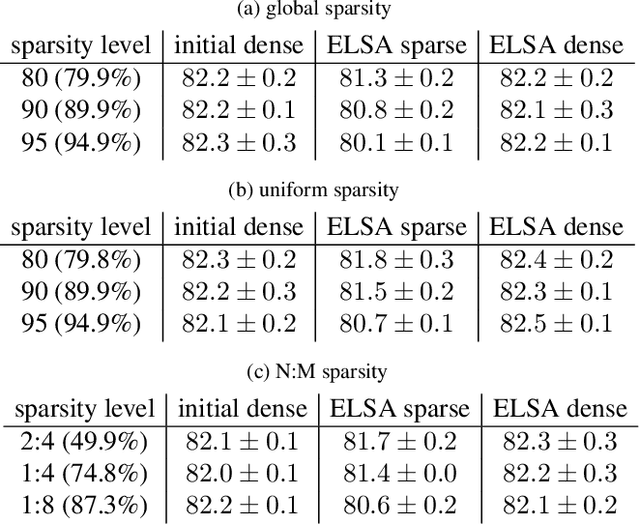

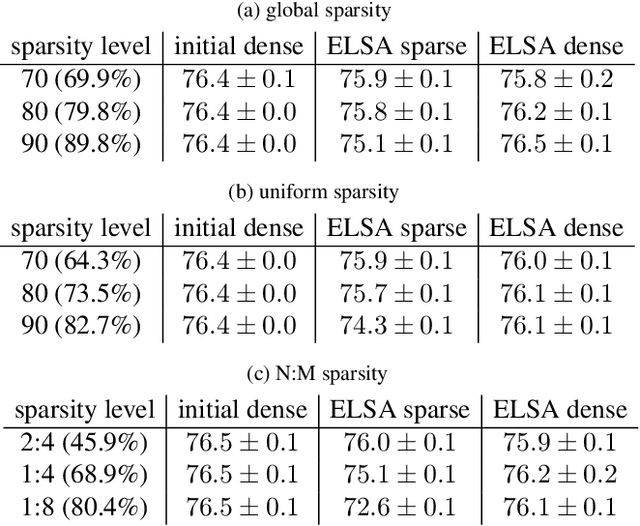
We present ELSA, a practical solution for creating deep networks that can easily be deployed at different levels of sparsity. The core idea is to embed one or more sparse networks within a single dense network as a proper subset of the weights. At prediction time, any sparse model can be extracted effortlessly simply be zeroing out weights according to a predefined mask. ELSA is simple, powerful and highly flexible. It can use essentially any existing technique for network sparsification and network training. In particular, it does not restrict the loss function, architecture or the optimization technique. Our experiments show that ELSA's advantages of flexible deployment comes with no or just a negligible reduction in prediction quality compared to the standard way of using multiple sparse networks that are trained and stored independently.